
Experiments on the fan conversion team
At the beginning of this year a small team at GameChanger was created with the mission to evaluate opportunities for optimizing our conversion rates for premium fans of teams, in anticipation of the 2015 amateur baseball and softball season, which peaks every year around April and May. We knew there were plenty of opportunities to explore, given that fan conversion had never been a top priority and there was a general belief that many aspects of our conversion flow could be vastly improved. In fact, many people from every area in the company started volunteering ideas, and we got to a point were he had a really long list to start working with.
With no shortage of ideas and potential opportunities, and the fact that we only had about two months time to execute some of them, the biggest question we needed to answer was how could we select the ideas with the most impact on our fan conversion rates that had the lowest time cost? Timing was critical because after two months the season would be well underway and the peak would have passed. After that point, every project that made it out into production would have diminishing returns, so we really needed to work with that window of opportunity.
Under these constraints, we decided that our best approach would be to take all ideas and formulate them as hypotheses we could test. Then we would sort them taking into account their potential impact if they were successful and how long it would take us to implement them.
Once we had a prioritized list of ideas, we would treat each one of them as an experiment where we would test the hypotheses with as little implementation as possible. The idea was to make functioning prototypes that we could use in production for result collection, without taking into account aspects like code quality and maintainability.
In general most of our experiments took around one day to set up, and then we would let them run for about a week before we reverted the changes and started analyzing results. Only when an idea was validated and we knew that there was a very high chance that implementing it would meet our expected goals, would we start working on a real, permanent implementation.
For our first experiments we used Kissmetric’s AB testing library. We already used Kissmetrics for analytics data collection and reporting, so setting it up would be relatively easy and quick. The library’s functionality is pretty simple: you give it a name that identifies the experiment and a list of options and it will return a randomly assigned group from the list.
var group = KM.ab("experiment_name", ["control", "treatment"]);Once a user is assigned to a group, the library will always respond with the same group the user was initially assigned to. This is important because if users are placed in a different group each time, it would be impossible to conclude if a behavior was caused by exposition to one of the specific versions or the control.
After we divided our users into groups, we just needed to select what the success criteria for the experiment was (usually an event we were already tracking, like premium subscription purchases), and Kissmetrics would do the tracking and the reporting, letting us known when we had reached our desired sample size and if there was a statistically significant improvement of one of the treatments relative to the control.
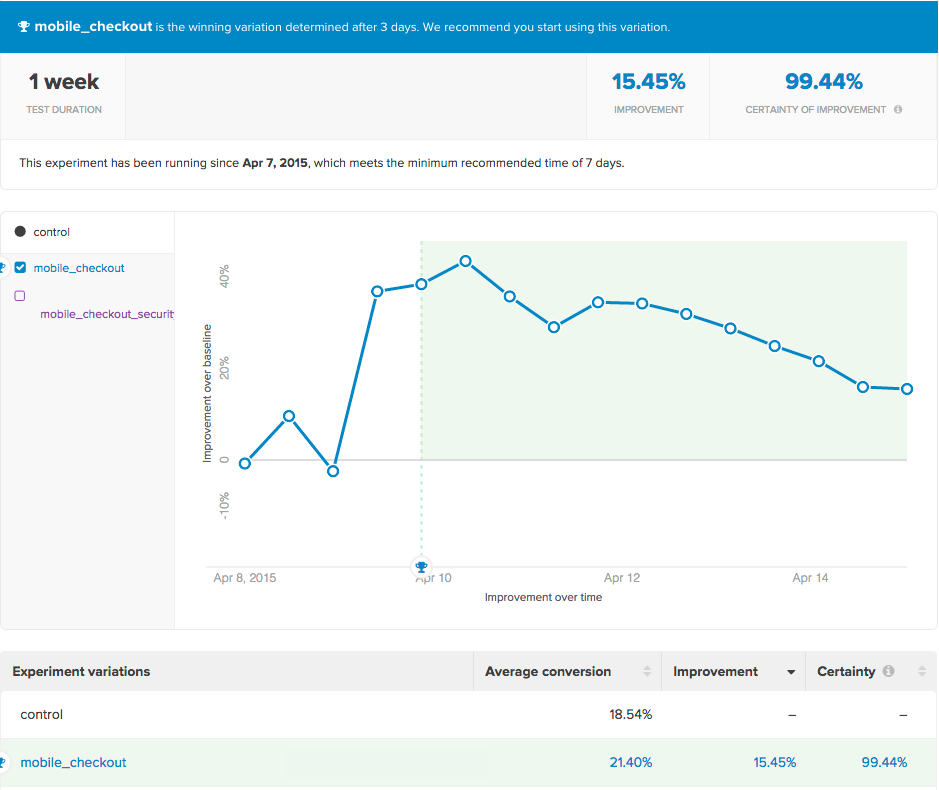 Kissmetrics AB Test Report
Kissmetrics AB Test Report
Limitations
We were able to launch a couple experiments using this, but we quickly noticed that Kissmetrics’ library wouldn’t work for most of our experiments. While the reporting was working very well and we were already tracking our success events on their site, the AB testing library had a couple of big issues.
For one thing, we found out that the service was quite slow. For the first experiment we had a one second timeout, after which the service would return the control group, as a default fallback. It was timing out almost half of the times it was called. We increased the timeout to three seconds, which can present a very noticeable delay for users, and the calls to the service seemed to timeout about ten percent of the time, which was better than before, but still too high.
Another big problem was that Kissmetrics’ AB testing functionality is currently only available through the front end JavaScript library. This made it hard to run experiments directly from our back end which is mostly written in Python. We needed this for some experiments that didn’t directly involve the website, like changes in email campaigns.
These two problems made us realize that even with the very short time we had, it would be worth it to invest in building our own service that we could use for assigning users in groups for each experiment.
GC’s Experiments Service
The problem itself was very easy to solve: if the user is not yet on the experiment, randomly assign the user to one of the group options, otherwise respond with the group the user is already assigned to. A very simple web service with some basic storage would do the trick.
Thanks to GameChanger’s amazing micro service architecture, we were able to build and release this to production in one day. The web service is written on Node.js and it’s backed by a DynamoDB database hosted on Amazon. It has a REST API that can be consumed from any part of our stack.
Given that most of our code is written in Python, we also wrote a Python client for calling the service. The interface is somewhat similar to Kissmetrics’: provide an experiment name, a list of group options, and an identifier for the user and it will return a group for that user in the experiment. The groups will be uploaded automatically to Kissmetrics by the client so we can still use their analysis and reporting tools.
group = get_experiment_group.('user_id', 'experiment_name', ['control', 'treatment'])The fact that this service was hosted in the same virtual cloud as the rest of our stack, and that it was written with performance in mind meant that we are consistently getting responses in under 50 milliseconds.
The traffic pattern for this service is very hard to predict. At any point in time the service could sit completely unused with zero traffic if there are no experiments running, or it could have very high traffic if, for example, a very popular feature is being experimented on. For this reason it relies heavily on Amazon’s EC2 autoscaling, and it is designed to fail gracefully. When anything goes wrong, the user won’t notice and will simply be assigned to a designated fallback group.
Sample case: redesigned checkout page
Why is all of this important? Going back to the beginning, we wanted to be sure that our assumptions were correct before actually dedicating engineering resources to developing any of the ideas we had on the board. If one of them didn’t provide a really meaningful conversion lift during testing, it was discarded and we could move on to the next one.
One experiment we were glad we tested before building was our checkout redesign. The hypothesis was that the checkout page was cluttered with information and provided many ways out, and this was hurting conversion. It had testimonials, a premium features list, a satisfaction guarantee and more. Some of these pieces of information had links to other pages on our website, which meant that checking out for a premium subscription was not an enclosed experience. This is generally agreed to be undesirable for a checkout page.
The team came up with a much cleaner and, in my opinion, better looking design. Everyone on the team though that this experiment would be a huge success, but as it turned out, our customers disagreed. After a couple weeks of running the experiment and three different iterations on the design, the results showed that the treatment group performed consistently worse than the control. People converted about 10% better on our old checkout page.
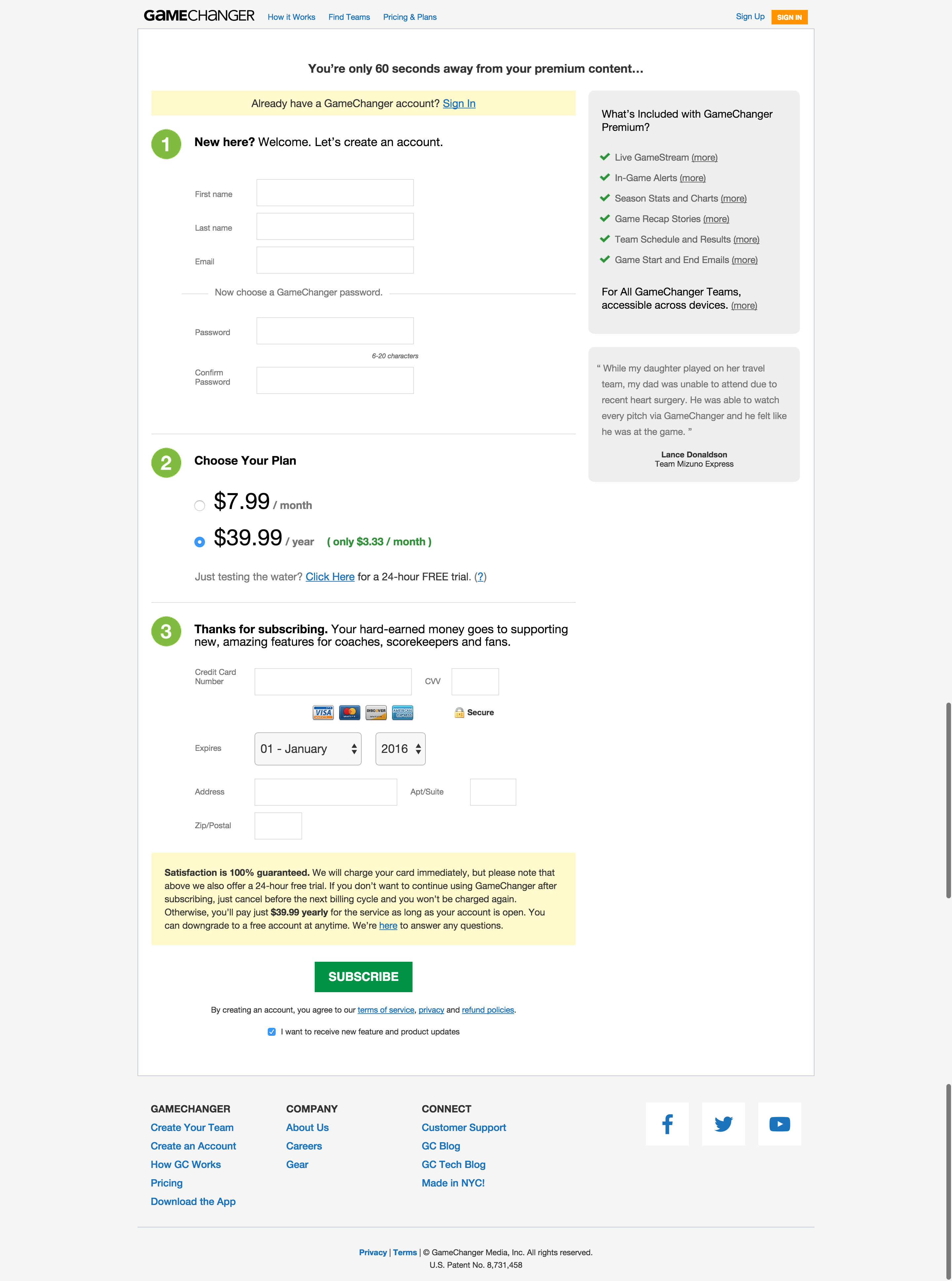 Current checkout page
Current checkout page
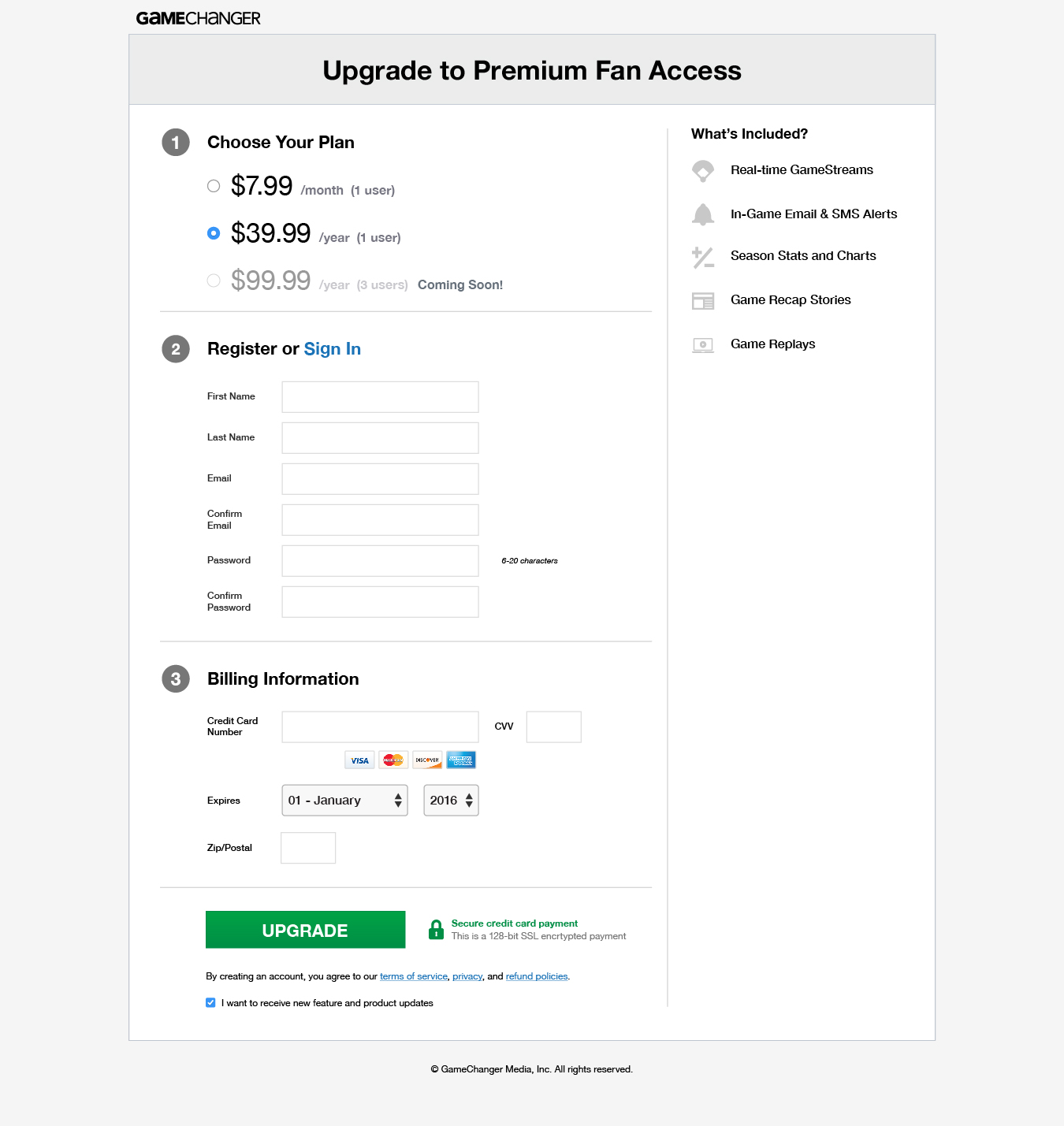 New design proposed for the checkout page
New design proposed for the checkout page
Conclusion
This example was eye opening. It showed us the importance of testing the things we want to build before committing them. It’s important to get as much information as possible early in the process so time isn’t wasted building features and making changes that customers won’t value.
We also had many successful experiments that were built after the experiments presented successful results, like making paywalls and the checkout page optimized for mobile devices. Even in those cases, we realized that performing a test before actually building the features was very useful to estimate the quantitative impact that a change could have on our goals.
This approach was very successful for us. The experiments service is used regularly by teams at GameChanger as a tool to help us understand our users and the impact that each new feature has on their behaviors, and ultimately, our goals.