
At GameChanger (GC), we recently decided to use Kafka as a core piece in our new data pipeline project. In order to take advantage of new technologies like Kafka, GC needs a clean and simple way to add new box types to our infrastructure. This is the second in a series of 2 blog posts I will be doing that explore this concept. This blog post is a direct follow up to my first blog post which covered the 5 steps for adding a new box type to GC’s infrastructure.
This post will cover the specifics of how I added a Kafka cluster to our production infrastructure. At GC, our Kafka cluster consists of 3 box types: Kafka boxes, Zookeeper boxes, and SchemaRegistry boxes. Below you can see the basic setup of our Kafka cluster. Each box has a different job to make the cluster work.
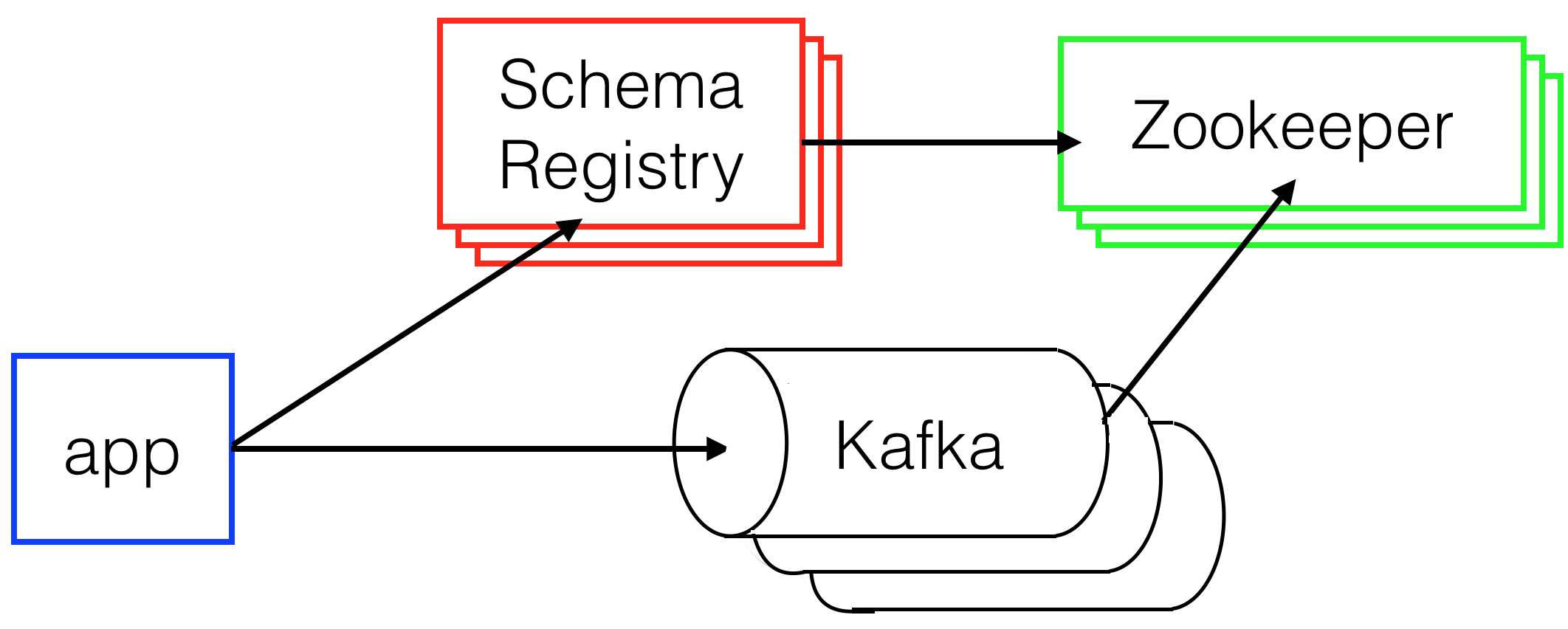
Zookeeper boxes are used by both the Kafka boxes and the SchemaRegistery boxes to access and store cluster membership. For example, if a new Kafka box comes online, it registers itself with the Zookeeper cluster and gets information on what Kafka boxes are currently alive. The next time a different Kafka box accesses a Zookeeper box, it will discover a new box has joined the cluster. The old box will get the IP address and the port of the new box from the Zookeeper cluster, allowing it to talk to the new box.
SchemaRegistry boxes are a Confluent system used for migrating, validating, and updating schemas for your Kafka topics. Each time one our apps wants to send a message to Kafka, it first makes sure to register a schema with the Schema Registry. This registration step allows GC to make sure the data being sent is of the right format and any changes to the schema are backwards compatible.
The final boxes, as you might expect, are the Kafka boxes. Kafka is a distributed, partitioned, replicated commit log. Kafka can act as a queue, provides pub sub functionality, and under certain circumstances allows for ordering of messages sent to it. All of these properties make it very useful for our data pipeline.
To get the Kafka cluster up and running, all three boxes needed their own new box type. I will cover the specific setups for all three.
1. Create a new AWS launch config
The first step when I added the new boxes was trivial. All three launch configurations were set up using AWS Console.
- I went into AWS Console
- Clicked
EC2 - Clicked
Launch Configurations - Clicked
Create launch configuration
From here, I specified GC’s standard AMI and a simple box type. The real configuration and setup happened in the final 4 steps.
2. Create a launch script that sets up a Docker box.yml
As mentioned in my first post, box.ymls allow specification of app specific configurations. Kafka, Zookeeper, and SchemaRegistry all needed to set specific ports and environment variables to run properly. Some of the most important environment variables were the urls for the Zookeeper boxes. These urls were needed by Kafka and SchemaRegistry to keep track of which boxes were in the cluster. The box.ymls also needed to expose ports outside of the Docker containers. These ports aligned with the ports specified in the docs for each system (9092 and 9997 for Kafka. 2181, 2888, and 3888 for Zookeeper. 8081 for SchemaRegisry). The box.ymls for all three systems can be seen below.
- Kafka:
kafka:
elb: kafka-production-vpc
image: <gc_docker_registry>/kafka
containers:
kafka:
ports:
9092: 9092
9997: 9997
env:
JMX_PORT: 9997
JVMFLAGS: -Xmx4g
ZOOKEEPER_SERVER_1: <zookeeper_box1_ip>:2181
ZOOKEEPER_SERVER_2: <zookeeper_box2_ip>:2181
ZOOKEEPER_SERVER_3: <zookeeper_box3_ip>:2181
LOG_DIRS: /var/kafka/data
CREATE_TOPICS: "false"- Zookeeper:
zookeeper:
image: <gc_docker_registry>/zookeeper
containers:
zookeeper:
volumes:
/var/zookeeper: /var/zookeeper
ports:
2181: 2181
2888: 2888
3888: 3888
env:
JVMFLAGS: -Xmx4g
ZOO_LOG_DIR: /var/log/zookeeper
ZOOKEEPER_SERVER_1: <zookeeper_box1_ip>:2888:3888
ZOOKEEPER_SERVER_2: <zookeeper_box2_ip>:2888:3888
ZOOKEEPER_SERVER_3: <zookeeper_box3_ip>:2888:3888- SchemaRegistry
schema-registry:
elb: schema-registry-production-vpc
image: <gc_docker_registry>/schema-registry
containers:
schema-registry:
ports:
8081: 8081
env:
JVMFLAGS: -Xmx4g
ZOOKEEPER_SERVER_1: <zookeeper_box1_ip>:2181
ZOOKEEPER_SERVER_2: <zookeeper_box2_ip>:2181
ZOOKEEPER_SERVER_3: <zookeeper_box3_ip>:2181
COMPATIBILITY_LEVEL: backward3. Create an image that will be the base of a Docker container
Docker provides a simple way to specify a set of steps needed to create an image; a Dockerfile. Kafka, Zookeeper, and SchemaRegistry all had Dockerfiles with very similar structures. First, the Dockerfiles needed to load an application specific configuration file (ASCF). The ASCFs were used to specify what settings the box would run with. As an example, the Kafka ASCF described the broker.id for the box, where on the file system to save topic data, and the default replication factor. Second, environment variables that were specified in the box.yml, needed to be set in the ASCF file. For instance, all of the Zookeeper urls specified in the box.ymls were written into their respective ASCFs. Finally, the process binary was run with ASCF as an argument. The ASCF for all three of the new box types can be seen below.
- Kafka
broker.id=BROKER_ID
zookeeper.connect=ZOOKEEPER_CONNECT
log.dirs=LOG_DIRS
delete.topic.enable=true
default.replication.factor=3
log.cleaner.enable=true
log.retention.hours=2160
num.partitions=64
auto.create.topics.enable=CREATE_TOPICS- Zookeeper:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/zookeeper
clientPort=2181- SchemaRegistry
kafkastore.connection.url=KAFKASTORE_URL
avro.compatibility.level=COMPATIBILITY_LEVEL
debug=true4. Scale new boxes with an autoscaling group
Much like step 1, step 4 was done through the AWS console.
- I went into AWS Console
- Clicked
EC2 - Clicked
Auto Scaling Groups - Clicked
Create Auto Scaling group - Based my auto scaling group off of the Launch Configuration from step 1
Once my new auto scaling groups were set up:
- Selected my autoscaling group from the list of groups
- Clicked
Edit - Changed the value in
Desiredto my desired number of boxes (3 for all three box types) - Clicked
Save
After about 15 minutes, I had my new box types!
5. Set up security groups
The final step, setting up security groups (SGs), ended up being one of the most challenging parts of the whole setup. This was due both to my own inexperience, and some nonintuitive SG rules that I had to learn. Initially I set up rules that let the boxes talk to each other on the ports exposed in the box.yml. After I first set up these SG rules, I was getting into strange split brain scenarios within the Kafka cluster. I could not figure out why this was happening until I learned that two boxes of the same SG (say Kafka) cannot inherently talk to each other. I needed to set up a security group rule to allow this communication. After I learned this, it was easy to get the isolated cluster up and communicating. I was still missing one key piece though. I needed to set up rules so that the application boxes could talk to Kafka. This enabled me to send messages from our web and api boxes to Kafka. This allowed me to actually use the new Kafka cluster!
Overall, the process to setup the Kafka, Zookeeper, and SchemaRegistry boxes took a few hours for each box type. It took a total of a day and a half to get a simple Kafka cluster up and running. A lot of that time was spent in each system’s docs, not on getting the boxes themselves setup. The process was quick and easy because of the simplicity of the GC production infrastructure. This infrastructure has allowed us to add new systems as needed, upgrade existing systems, and experiment with new technologies that we believe may be valuable, like Kafka.