
At GameChanger, being able to deploy our changes quickly and reliably has always been important. Over the past few months on the platform team, we’ve been working to build a simpler and more reliable deployment pipeline to support our product teams in shipping code with speed and reliability.
In this post, I’ll go over the system that we have in place now, and some of our recent improvements.
How deploys our work

High Level Overview
At a high level, the core of our deployment process involves shipping a docker image to some EC2 instances, and then starting a container with that image.
Our main code repository contains a Dockerfile with the required configuration for our live app. After each new commit to our main code repository, Our CI process will docker build a new image with a new tag, and push it to our internal docker registry. During a deploy, we pull that image on the relevant EC2 instances, and start a container with it. Once we have a running container, we register that EC2 instance with a load balancer, and start serving traffic.
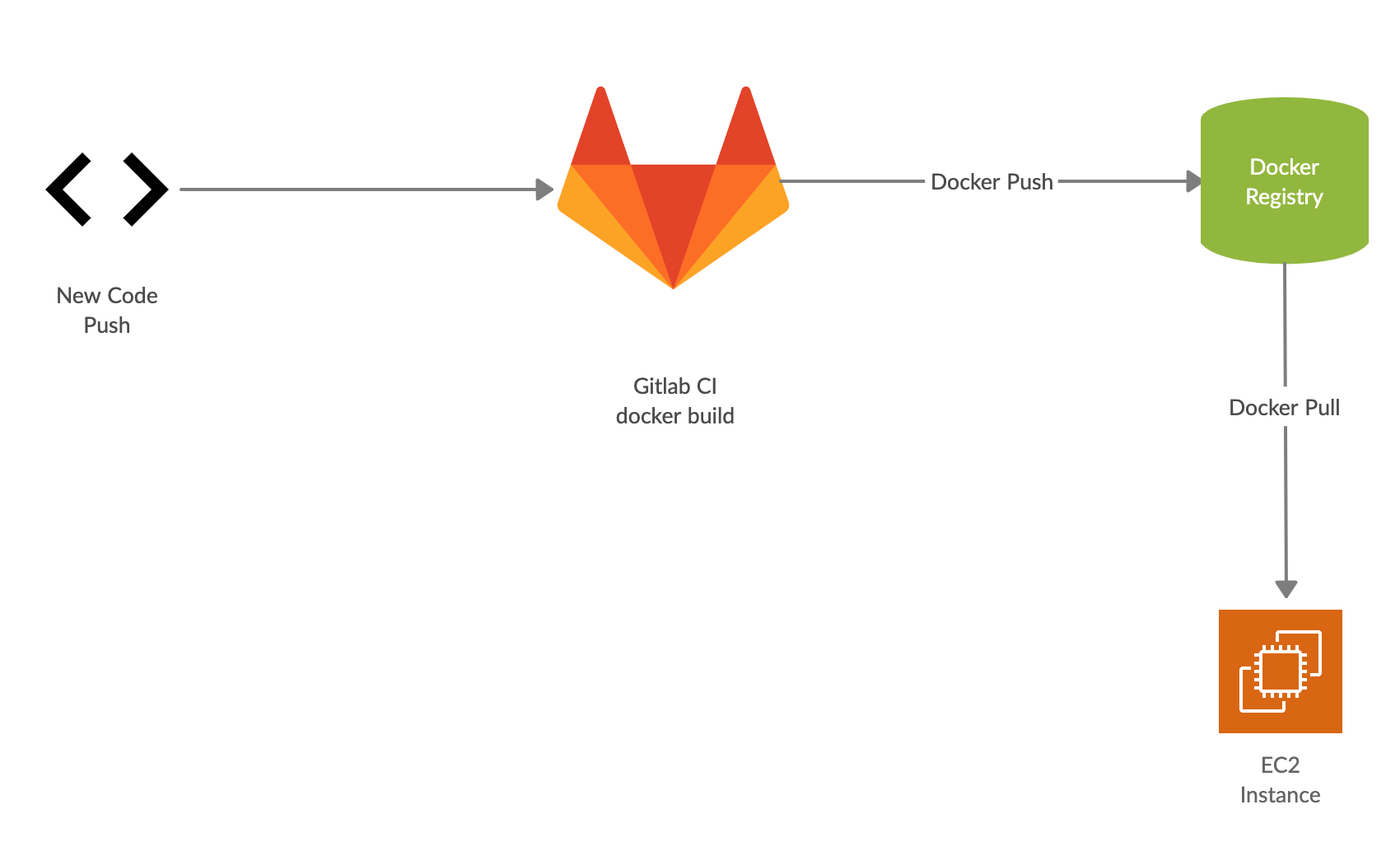
While the high level is straight forward, there’s a lot of work that goes into making sure our deployments happen safely, and at the right time.
Once a new image has been pushed to our registry by our CI process, we need to notify all our currently running instances that there’s a new version to deploy. Each commit corresponds to a new docker tag that’s created during the build. Once the tag is created, we notify our internal deployment service of the new version. Once our tag is pushed, and our deployment service is aware of it, we tell our deployment service to start a deploy, which will send a message to all of our running EC2 instances.
Serf Messages
We use Serf to send that message out without needing to directly contact every instance. The message we send contains a role and environment. The role is the name of a docker image we want to deploy a new version of, and environment will be production or staging depending on where this deployment is headed.
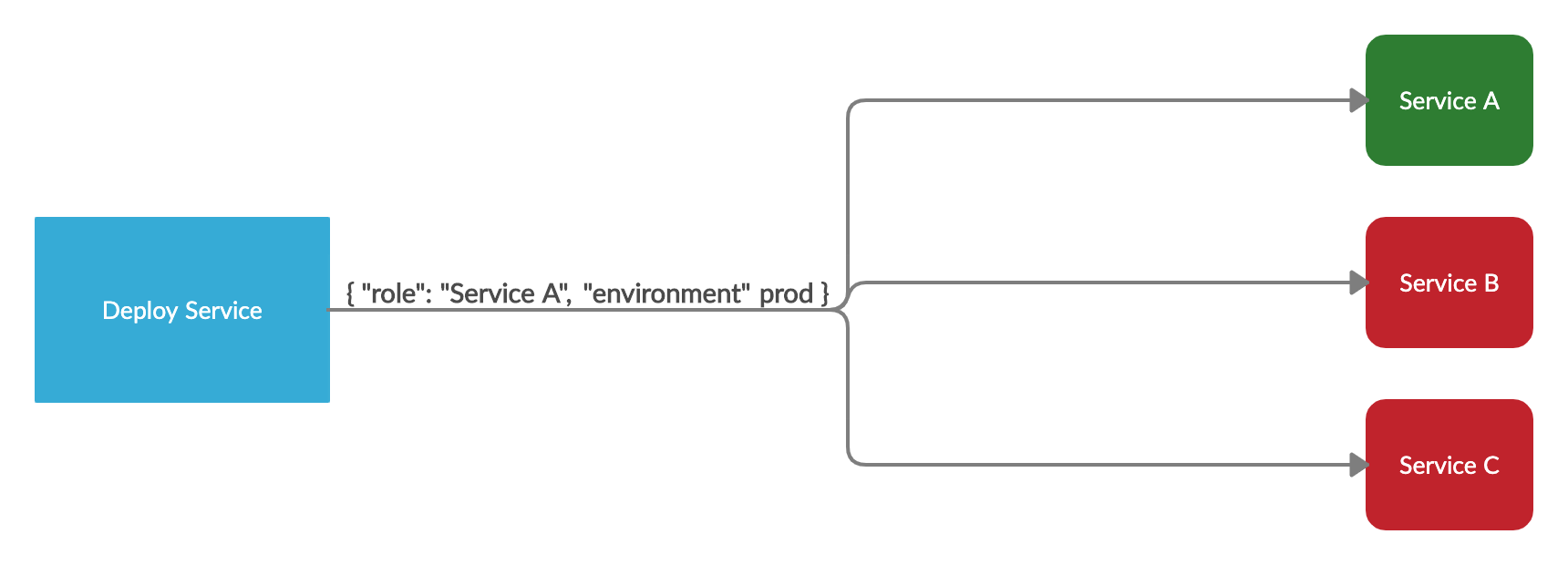
Through the Gossip protocol, the Serf message will propagate across our entire cluster in a short period of time, but only the boxes that are responsible for deploying the specified image do anything when they get the message. That’s because each box runs a serf agent, which listens for our messages and is given Serf tags when it’s initially provisioned. Serf tags allow us to associate a box with the docker images that should be deployed there. In our infrastructure, each box has a images tag, which is a list of docker images that should be deployed there. We’ll only start a deployment when the serf tags match the details in the deployment message.
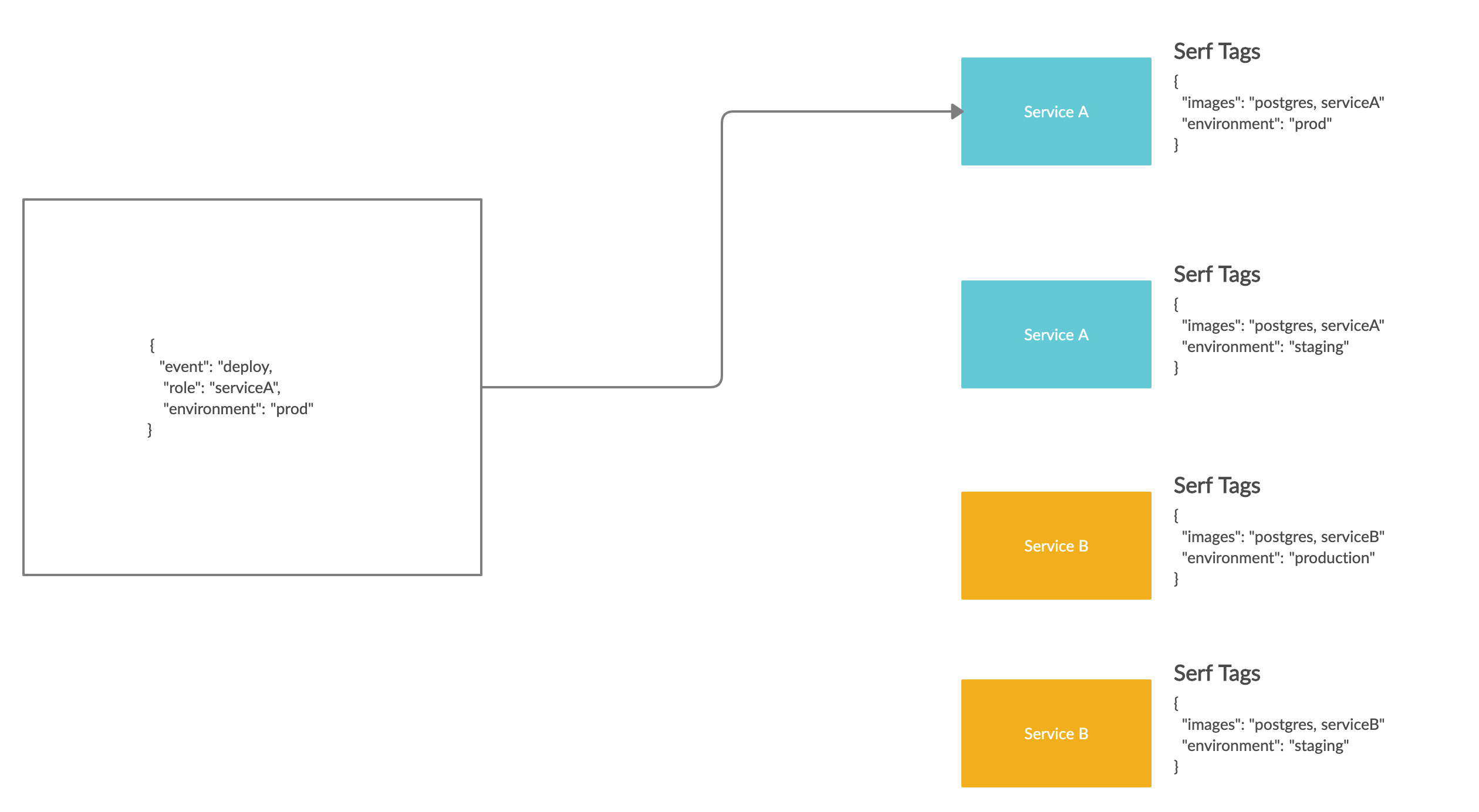
Serf also allows you to configure event handlers for certain messages. An event handler is just a script that executes when a certain serf message is received by an instance. Each of our boxes has the same event handler for deploy serf messages, which is what starts the execution of our deploy script.
Deployment Locking
Before we can start creating the new containers, we need to make sure that it’s safe to start the deployment. During our deploy process, our live containers will stop serving traffic and be removed from our load balancers for a period of time. Since all of our instances receive the deploy message at the same time, they could all start deploying at once, and bring down our application until the deployment is done. In order to make sure that doesn’t happen, we use a locking system to ensure only 1/3rd of our boxes for any given service can be deploying at once.
First, each box uses serf to figure out the current size of the deployment (how many instances are involved) based on the environment and service name. Serf has a built in members command that allows us to see all of the other boxes that are active and running serf agents. We use this and the serf tags to get the count of live boxes we are going to deploy on. We also store this number in a redis key, and decrement it whenever a box is done deploying, so that when it reaches 0, we know a deployment is completely finished.
Once we have that, we know how many locks should be available, and each box will simultaneously try to acquire the first deployment lock. Each “lock” is represented by a single redis key with a suffix. We start with 1 as the first lock suffix, and increment from there. We use a SET NX to represent acquiring a lock, which will set a key only if it does not already exist. With only 1 instance of redis, only 1 box can succeed at this operation. The box that successfully sets the redis key will have acquired a deployment lock.
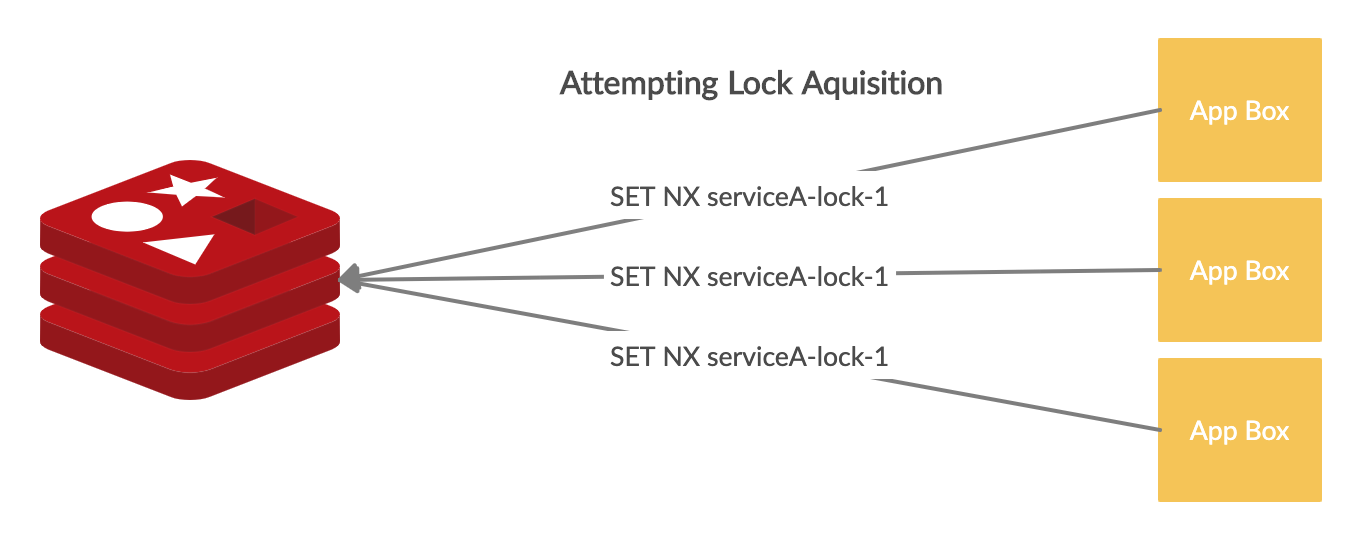
The box that succeeds can start deploying, and the rest of the boxes, will try acquiring other deployment locks by if they are available (since we only deploy a 3rd at a time, there are only cluster size / 3 locks available). If there are other locks available, the rest of the boxes will try incrementing the lock key suffix, and attempt to acquire the next lock key.
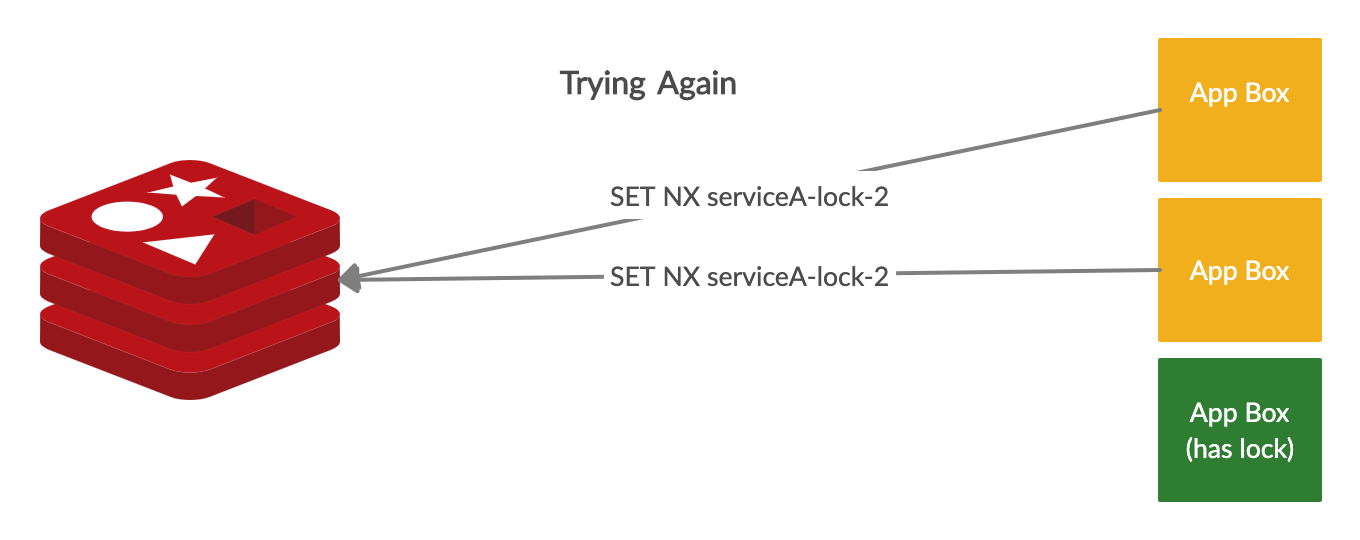
If there aren’t any locks available, the remaining boxes will poll redis until a lock frees up. Once a box is done deploying, it will release the lock it held by deleting the redis key it created.
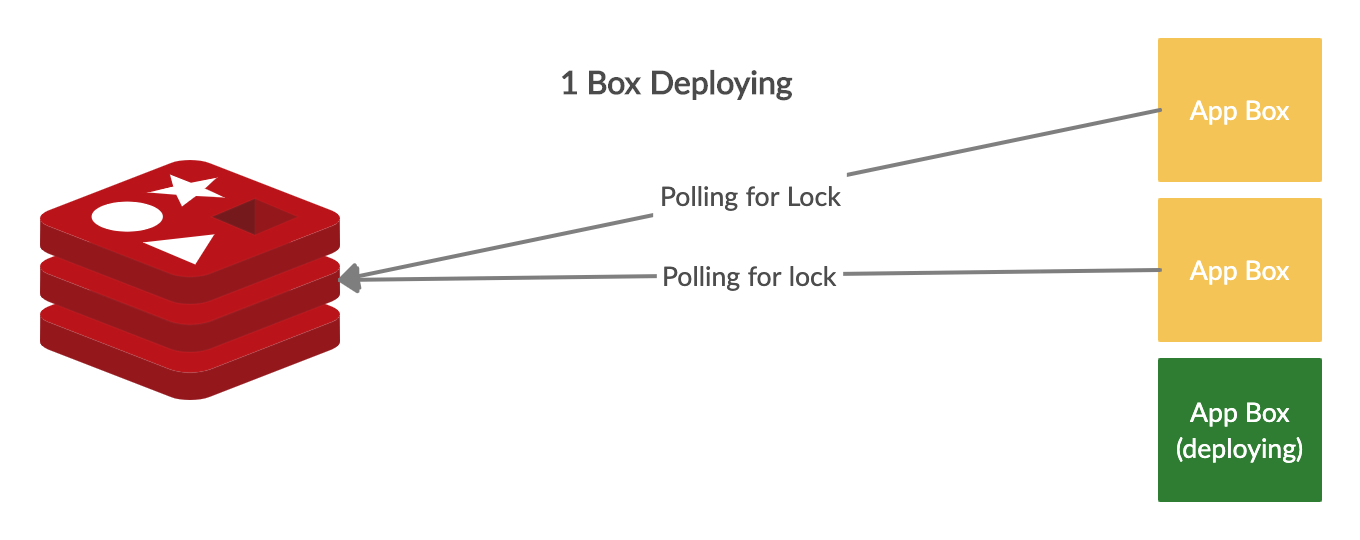
If there’s an issue during deployment, or a box freezes or shuts down, we don’t want to prevent future deployments, so we set a TTL on the lock key of 15 minutes, to prevent holding up any deployments if we have to terminate an instance.
Once a box has a deployment lock, it can start running our deployment script. Since our serf message doesn’t contain which tag we want to deploy, we first reach back out to our deployment service, which tells us which tag to pull from the registry. Once we know the right tag, we can pull it and start some containers. Each of our boxes is provisioned with a docker-compose file, that tells us what containers we need to run on that box, what environment variables they need, and how they’re connected. The deployment script uses docker-compose to understand how to start up our container and it’s dependencies.
Because each service has it’s own compose file, starting up an application and it’s dependencies is as simple as running docker-compose up -d
If everything goes well, after our container starts up, the instance will register with our load balancers, and start serving traffic!
Blocking bad deploys
Before some recent changes, when we started a deployment, we would continue deploying to all of our infrastructure even if there were issues with the image. In cases where we might be deploying a faulty release, there was no way to stop it from rolling out to all of our boxes first, even if we had a fix ready to go.
One of the recent improvements we’ve made, has been preventing bad deploying from rolling out to all of the boxes for a service. Since we only deploy a 3rd of the cluster at a time, there’s no sense in continuing to roll out deploys that we know are broken.
To make this work, we take advantage of our locking mechanism. If a deploy is broken (for example: if we can’t start a container with our new image), we set a special key in redis that all of our currently deploying boxes look for as they’re waiting for a lock to become available, telling them to cancel the deployment. Once this key is set, the other instances stop deploying, and call out to our deployment service to mark this release as “broken”.
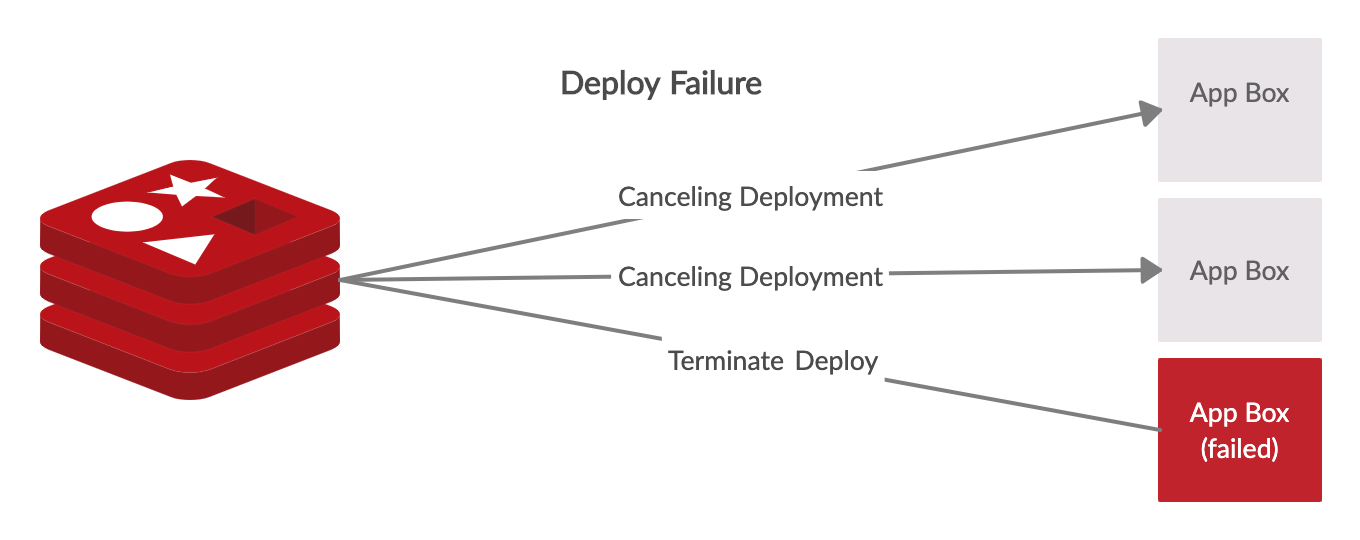
This new feature also allows us to make sure deploys work in lower environments first before automatically promoting them to production. Our pipeline will first, kick off a deploy to a staging environment, and if there are no issues, automatically kick off the production deploy.
Wrap Up
Our recent improvements have added some reliability and more visibility into our deployment pipeline, but the system is still evolving. Down the line, we’d like to look at tying in our APM metrics to deployment, and improving our detection of “broken” releases. We’re continuing to work on delivering a best in class deployment system to support shipping releases as quickly and reliably as possible!