
You’ve finally got everything working in your staging environment: the new systems talk to each other, everything is running smoothly, your dashboards are beautiful and pristine.
Now you need to get it into production with zero down time and no interruptions.
And then you realize, you’ve no idea what you actually did in your staging environment.
Let’s talk about infrastructure
I don’t consider myself an “infrastructure lady;” it’s just not my jam, and that’s fine. However I have had to learn a lot about our infrastructure for setting up our new data pipeline system — and I don’t just show up to learn the minimum.
I come to m a s t e r.
IaC, or infrastructure as code, is the idea of setting up your infrastructure using definition files, code, and standard programming practices. In a way, it brings infrastructure to those of us who might otherwise be overwhelmed by what’s going on and what we’re suppose to do. Why manually enter configuration values when you can store them in a YAML or JSON file in a git repo? Suddenly you can see its history, you can search it, and it documents itself to a certain extent.
This last point is of particular interest to me, as so much of the data pipeline is just how the systems work together, what the configurations are to facilitate this, and and documenting how all this works. If — if — we could have our data pipeline and all its friends live in some straightforward, self documenting IaC setup, it would make it easy not only to remember what we did but also to onboard someone new to the system and to deploy it to different environments with high confidence that it’ll work.

At GameChanger, that meant making three systems work together: Terraform, Consul, and Ansible. Terraform sets up what we want the landscape of our machines to look like. Ansible sets up what we want the landscape on our machines to look like. And Consul is the new kid in the collection, just here to have a good time and be helpful.
Leibnizian optimism
Alright, so we know what our tools are and we know what we want to do:
- using Terraform, Ansible, and/or Consul in some way
- be able to spin up the full data pipeline with a single command
- configurations should make their way to all the systems that need them automatically
- and we should be able to use this tool we produce for multiple environments
As our Ansible setup will work within the confines of what Terraform sets up for it (can’t set up a machine that doesn’t exist yet), Terraform is where we’ll want to start. And this makes sense on a second level too since a lot of what Terraform will output, like the addresses to services it’s brought up, will be used by Ansible to set configuration values. Therefore, we need those machines set up before we can configure them.
Starting with Terraform, there were a few key things I came across that helped me put together a plan of an ideal end state:
- you can pass in input variables
- you can pass out output values
- you can set up a module, which functions kind of like a class
Well, I know what I’d do if I was writing a class to accomplish what I want: take in a few values that specialize the pipeline for the specific environment I want to set it up in, do all the internal secret sauce, then send back the configuration values that are needed for other systems to connect to the pipeline. Running it would thus get me a pipeline “object” which is, ultimately, one of the few things I want in this world.

That and a cat.
What we’ve got now is shaping up to be a nice little plan: make a Terraform module; pass in the values that make it unique for an environment; pass out the values that are needed to connect to it. We’ll then need a way to get those values to Ansible, probably using Consul, but one foot in front of the other.
Let’s get ready to M O D U L E
A nice thing about Terraform is it figures out the order to run your blocks of instructions in, meaning you can structure your file so that it makes sense to humans.
Our Terraform module had a head start in that, before I made the module, I’d set up bits and pieces of the pipeline in different Terraform files that didn’t work together but could be refactored into one location. That’s because Terraform is, despite what it might seem, oddly easy to work with once you get used to reading the documentation and using the examples to make your own version of whatever you need. (Sure, it inevitably needs its own special snowflake version of something vaguely YAML-esque to work, but at this point we all know that’s how large tech projects assert dominance in the world.)
Starting with what the module needed to do helped guide figuring out what needed to go in and come out:
- bring up a hosted Kafka with its configurations
- bring up a Schema Registry
- bring up a Kafka Connect
- make sure these services can talk to each other
- make sure other services that should be able to talk to these three pieces can
- bring up any S3 buckets we want to make use of
- set up nice DNS records to make it easier for humans to know what they’re talking to
Sure, that’s a long list, but once the module is set up, it’ll be only one thing that handles all of the interconnectivity, which is thus also documented by the module. That would mean we’ve already covered a huge amount of our ideal end state.
Layered like an onion
I started at the logical core and worked my way out for the Terraform module, making notes of what I’d want to have passed in as I went. Everything of interest lived in either main.tf, where I did all the fun Terraform adventuring, or vars.tf, where I documented what a user of the module would need to know.
// Must provide
variable "pipeline_name" {
default = "test"
description = "The value to use in naming pieces of the data pipeline. This will most likely be the name of the environment but might also be another value instead."
}
variable "environment" { }
// …
// Can override
variable "kafka_version" {
default = "2.2.1"
}
// …Sample from the vars.tf. Using the description field was particularly helpful in ensuring the ability to make sense of the module without further, separate documentation. I also split the variables into what must be provided at the top and what could be provided at the bottom.
Comments not only separated each block of Terraform work in main.tf but also let me put in markdown-style links to where further documentation was, in case someone wanted to read more about, say, the pipeline. I’d like in the future to go back and break down main.tf into smaller files, one for each chunk of work, but that’s more advanced than my current Terraform skills so will wait for another day.
My favorite thing I’ve learned from Terraform is how many AWS resources can have tags: EC2, MSK, security rules, if you can name it, you can probably tag it! These tags are helpful not just while in AWS, figuring out what is what and searching for something specific, but also can propagate elsewhere as a sort of shared configuration: Ansible can see tags but so can Datadog, for example. Now you can scope your host map, using only tags!
Imho the following tags are what I feel best capture what you need to know without going overboard:
- the
environmentyou’re in - the
jurisdictionthis piece is part of- for example this item could be part of the
data-pipeline, orci-cd, or maybe a collection of related microservices that, together, form one system
- for example this item could be part of the
- the
project_version, especially if you’re doing upgrade work - the
servicethis actually is under the hood - and the
purposeof this piece within the grand scheme of things
The difference between the last two might be something like service: msk and purpose: pipeline, or service: kafka-connect and purpose: extract. The purpose tag is like a shorthand, then, for what you’re trying to accomplish without getting bogged down in how you’re accomplishing it. I could change out MSK for a self-hosted Kafka, but the purpose of that piece would still be to function as the pipeline.
Sharing is caring
We have our Terraform module now. It’s beautiful. It’s orderly. It’s doing its best to prevent the universe from descending into chaos. We can bring up the whole thing with a single command. Checking our list of hopes and dreams, we now have:
- using
Terraform, Ansible, and/or Consul in some way be able to spin up the full data pipeline with a single command- configurations should make their way to all the systems that need them automatically
- and we should be able to use this tool we produce for multiple environments (50% done)

Aight, some progress, but… well, our output goes into our output.tf file but… that’s not somewhere Ansible can get those values, let alone other services. We need to work on that.
But oh! Remember that third service we can use? Consul? Time to shine.
If you search for using Consul with Terraform and Ansible, you will get this and this respectively. Those are not the pieces we want. What we want is to use just Consul’s key-value store functionality, which you’ll find in the same Terraform doc a bit further down but in a distinct part of the Ansible docs because it’s actually a completely separate part of the system. Go figure.
Well, if we can have Terraform produce the configurations into Consul, and Ansible consume the configurations from Consul… that should be what’s left on our list!
Declaring our values
Instead of the Consul keys block in Terraform, I actually found the similar sounding but slightly different Consul key prefix block in Terraform to be what I wanted, as it lets me group all my configurations in the most straightforward way possible.
// Consul
resource "consul_key_prefix" "data-pipeline-configs" {
path_prefix = "${format("data-pipeline/%s/%s/", var.environment, var.pipeline_name)}"
subkeys = {
"pipeline_cluster_name" = "${aws_msk_cluster.pipeline-cluster.cluster_name}"
"pipeline_cluster_version" = "${var.kafka_version}"
// …
}
}Sample of how Terraform outputs are pushed into Consul. Some of this was remembering the inputs originally passed in, but a lot of it was taking the values Terraform had helped create and remembering them for use later.
What’s the address for the Schema Registry? "schema_registry_servers" = "${aws_route53_record.schema-registry-dns.name}" set the value in Consul. What’s the name of the bucket I want to use as an archive? "archive_bucket" = "${aws_s3_bucket.archive.id}" set the value in Consul. You get the idea.
Combing through all the configurations I had set in Ansible and in different services, I was able to move all values that would ever change into Consul. This was useful in not just, for example, sharing what is the expected number of partitions a pipeline topic should have (pipeline_cluster_partitions) with services that should match that expectation, but also in having a place where a human can go look up all current values.
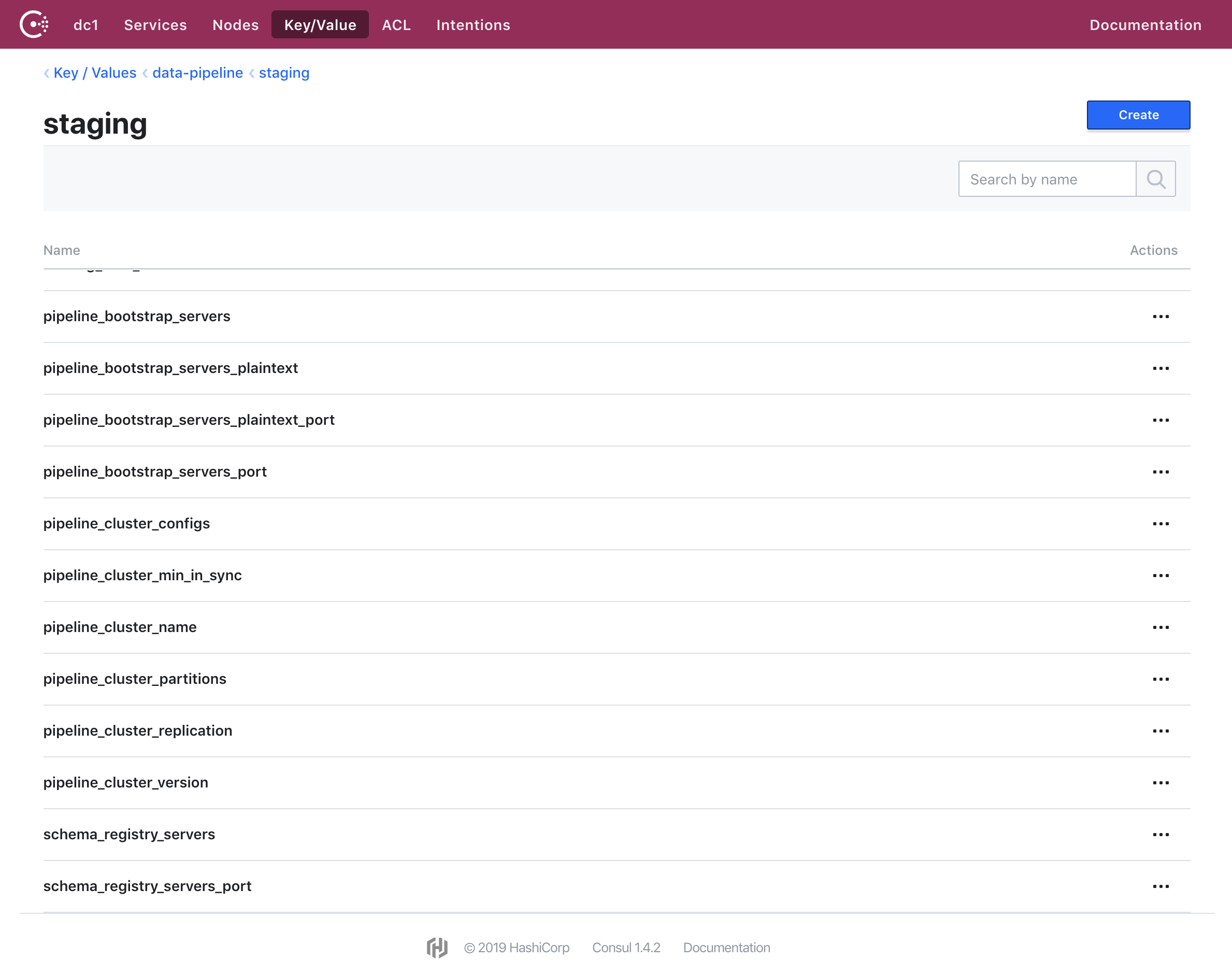
Example of what we’ve stored in Consul.
Once it was confirmed that all of the values were making it from Terraform to Consul, it was time to start using them.
Configurations for the lazy
As Ansible had been used to help determine what Terraform should put into Consul, it then became a matter of replacing the hardcoded values with getting the values from Consul: thus, never again would Ansible need to be updated for a configuration change.
Using Ansible’s Jinja support, all we had to do was change something like
KAFKASTORE_BOOTSTRAP_SERVERS: PLAINTEXT://boring-and-obtuse-record-name:some-port-you-keep-forgettingout with
KAFKASTORE_BOOTSTRAP_SERVERS: PLAINTEXT://{{ lookup('consul_kv', 'data-pipeline/staging/staging/pipeline_bootstrap_servers_plaintext').decode('utf-8') }}:{{ lookup('consul_kv', 'data-pipeline/staging/staging/pipeline_bootstrap_servers_plaintext_port').decode('utf-8') }}Sure, that takes up hella more space on the line, but it gets the values automatically. If you change what you want your port to be, just have Terraform update Consul! Ansible gets that update for free.
The eagle eyed among you will notice the .decode('utf-8') after each lookup. Funny story: everything came back with a b in front of it because of the way the lookup was parsing Consul’s values (they all came back as byte literals since we run Ansible using Python 3). The short answer to how to fix this is to force encodings. The long answer is… longer, and Ansible isn’t something I 100% understand so…

At least you can run Python functions easily in Ansible.
Wrapping up our project
Let’s check back in on our list:
using Terraform, Ansible, and/or Consul in some waybe able to spin up the full data pipeline with a single commandconfigurations should make their way to all the systems that need them automaticallyand we should be able to use this tool we produce for multiple environments
We did it people! We did it!

Now any system that needs to talk to the data pipeline can just ask Consul for the values using the very straightforward API, or let Ansible set up the values for them. Terraform can do everything its little heart desires in a sane way that humans can read and understand. Our data pipeline lives.
And best of all, our configurations have a single source of truth.
In summation
- a data engineer who doesn’t know a lot about infrastructure
- simplified setting up a complex, interconnected infrastructure
- and got configurations sharing between the different systems
- all in a self documenting way
- all in the same project
Now that, my friends, is called a victory.
Let’s launch this into production, shall we?