
As GameChanger’s data engineer, I oversee the data pipeline and data warehouse. Sounds simple, right? And at a high level, it is!
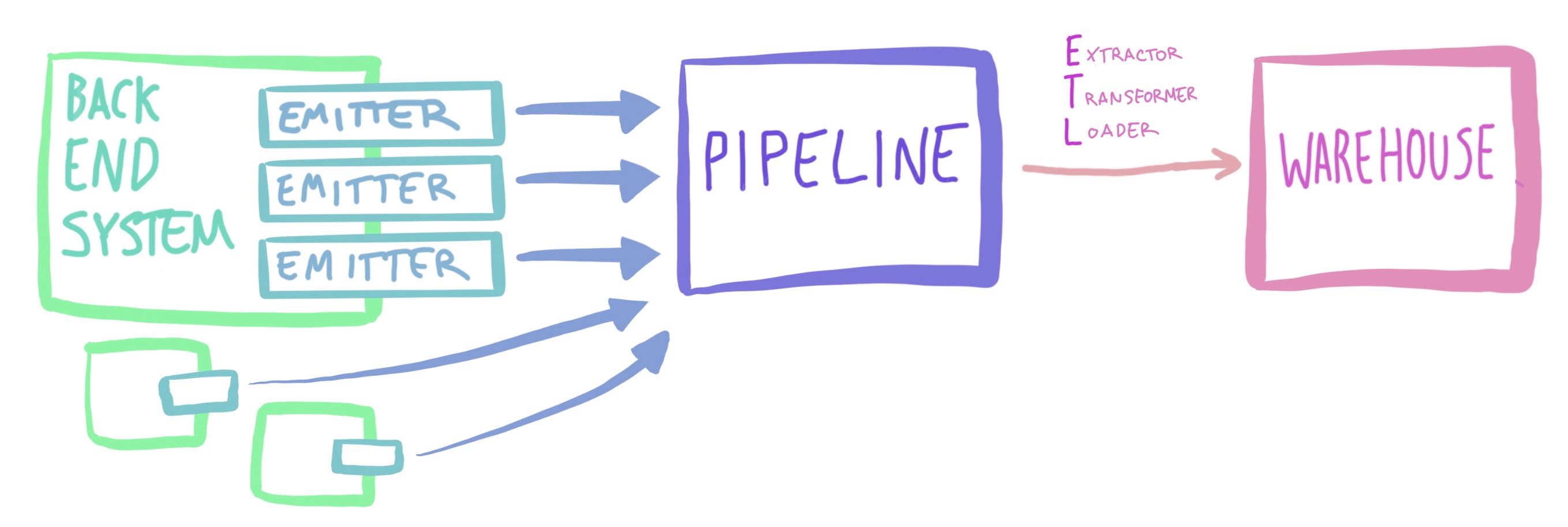
Fig 1.1: high level architecture diagram. Some complexity removed due to it being kinda boring for this post.
Producers produce into the pipeline, and our main consumer is the ETL job which moves data to our warehouse, enabling anybody to come get answers to their questions and see what’s happening across all our systems. Boom: easy.
Well, not quite.
Who owns what
Since data can come from any number of backend systems and teams, engineers are responsible for writing the setup that shepherds their data through the system: a producer that lives near their data, the pipe it travels through in the pipeline, and the warehouse table. This often means new data that I’m unfamiliar with arrives in our warehouse without me even knowing it’s been set up, which is actually kind of neat: the system should be so easy to work with that you don’t need the data engineer.
After a recent refactoring project, producers were made as simple as possible with removed boilerplate and plenty of tests to automatically catch the most common bugs engineers encounter. Typically, engineers have no problems with making their producers.

Fig 2.1: engineers before and after producer refactor project. Studies have shown that engineers prefer to be happy.
The pipe their data travels through is set up by filling in a form and pressing a button. Again, engineers typically have no problems with this.
It’s the warehouse table that becomes a pain point.
Follow the readme
There are two times non data engineers need to interact with warehouse tables:
- they’ve created a new producer which needs a table for their data to land in.
- they’ve updated an existing producer which needs its table updated as well.
The second point is trickier and easier to get wrong, but the first point proved just as difficult for many engineers and far more common, especially if the engineers in question had never made a producer before. The warehouse is a different database from the ones they usually interact with, it has slightly different (SQL) syntax than they might be used to, and the code must be written by hand instead of using a library to generate it. It’s also easy to miss that you’ve forgotten it when you don’t typically interact with the data warehouse.
So how bad is “bad”?
Why does it matter that the table exists? Well, if we look at how data crosses the pipeline-to-warehouse boundary, we find a gotcha.
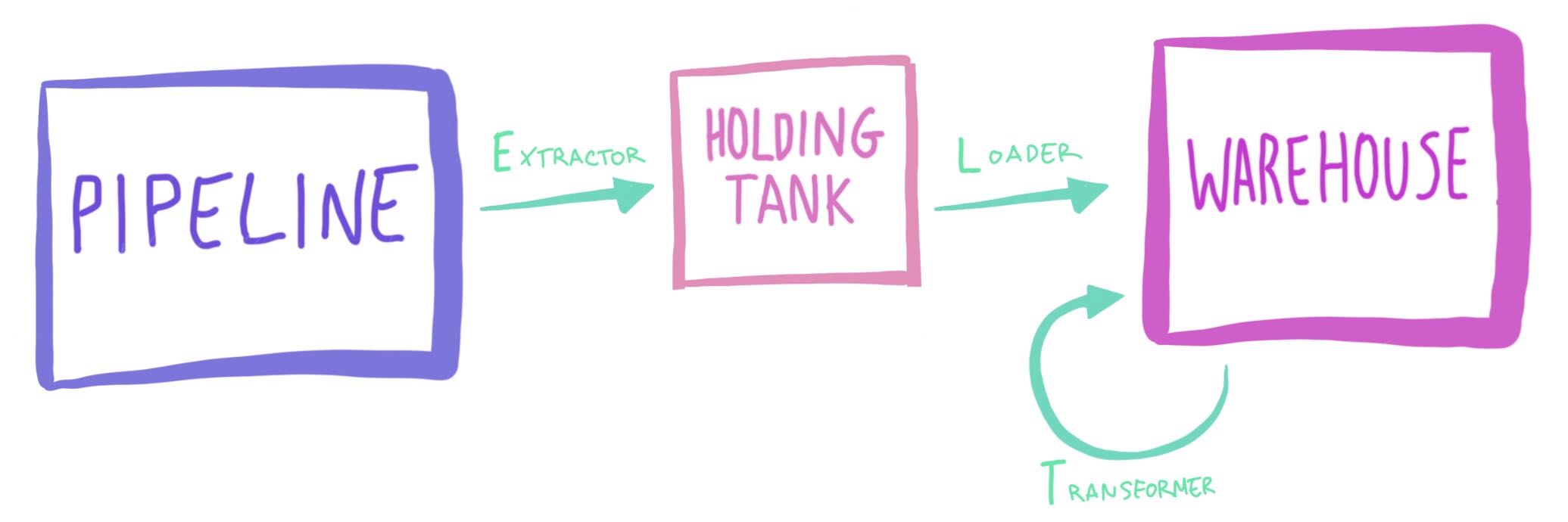
Fig 4.1: a gotcha in the ETL system. Unlike data, a gotcha cannot be turned into information.
Our warehouse needs a place for data to live, a home to call its own. If there’s no table for it, our loader isn’t able to move the data over: it builds up in our holding tank, never getting to the transformer.
Previously this caused our loader to become unstable, as it pushed data from the holding tank into the warehouse; our new version pulls data only if there’s a table, but the table is still key.

Fig 4.2: unmoved data. Many studies posit that data, unlike engineers, have no preference towards being happy, but I would disagree.
So if engineers often forget or struggle to create the table, the data won’t move without a table, and I don’t have the in depth knowledge of what this data is to make every table myself (or even that there’s new data coming through), what can we do?
Thought experiment: an ideal world
Let’s imagine what an ideal world would be for solving this problem: in this world, the table would be created automatically in the warehouse.
Well, what keeps us from that?
Firstly, we’d need to know the shape of the data to know the shape of the table.
Figure 5.1: the shape of things. Between systems, the same thing should have vaguely the same shape.
Actually this is something we already have: all data as it moves through the data pipeline must declare a schema, which is registered with a service that will happily answer the question, “what is the shape of x?”
Secondly, we’d need to be able to convert that schema to a table.
Alright, so say we had a way to convert a schema to a table, what else would we need?
There’d be a few gotchas around how to convert the schema fully: an integer is an integer and a boolean a boolean but is a string a VARCHAR(48) or a CHAR(36) or even a DATETIME in hiding? Plus our warehouse is distributed, so what do we distribute it on?
Let’s imagine we had a system that could make most of the table but not all of it: if we asked engineers to then finish the flagged portions of the table, would we have something pretty close to an ideal world?
One way to find out.
A touch of magic
To bring this project from high level to specifics, here are the pieces I needed to make work together:
- Our loader, which is written in Python.
- Github, which is where table creation files are reviewed before being automatically run when they hit
master. - Slack, to let engineers know that there’s a table in need of a review.
- Schema Registry, which stores our schemas.
Github, Slack, and the Schema Registry all have RESTful APIs which we could easily hit from our Python without much fuss, which meant not only was this doable but it shouldn’t be too crazy for other engineers to read and understand.
data_types = get_data_to_load()
tables = get_existing_tables_of(data_types)
missing_tables = data_types - tables
for missing_table in missing_tables:
schema = get_schema_for(missing_table)
create_statement = convert_to_sql(schema)
branch = create_branch_for(missing_table, create_statement)
pr_link = create_pr_for(missing_table, branch)
post_to_slack(missing_table, pr_link)Figure 6.1: pseudocode of bringing our ideal world’s solution to GameChanger.
The hardest part of implementing the above ended up being create_branch_for(missing_table, create_statement) as git commands are simple to do on a command line but required introducing a new Python library to achieve in the code. Instead of trying to make that work, I cheated and wrote a shell script — ironically, the first time perhaps that a shell script was the simplest implementation for everyone to understand.
echo "Checkout"
git checkout -b ${NEW_BRANCH}
echo "Add"
git add ${FILE_PATH}
echo "Commit"
git commit -m "Create migration for missing ${TABLE_NAME} table in warehouse."
echo "Push"
git push origin ${NEW_BRANCH}Figure 6.2: pseudocode of the shell script to assist our Python, which only had to add the waiting file and substitute in a few names.
As I was implementing and testing the code, other sticky spots arose (the Github API wasn’t playing nice for some reason but the Python library wrapping it was) as well as opportunities: I realized while writing convert_to_sql(schema) that I could flag the specific lines that needed an engineer’s attention with a simple -- Please verify this line! when there were strings or where the distribution key was defined.
Finally I found a way to add, not just a touch of magic to the system, but also a touch of fun with a little bit of personality in the pull request; this would go a long way in taking the PR from “a thing the system demands of you” to “a fellow engineer, albeit not human, asking for your help.”
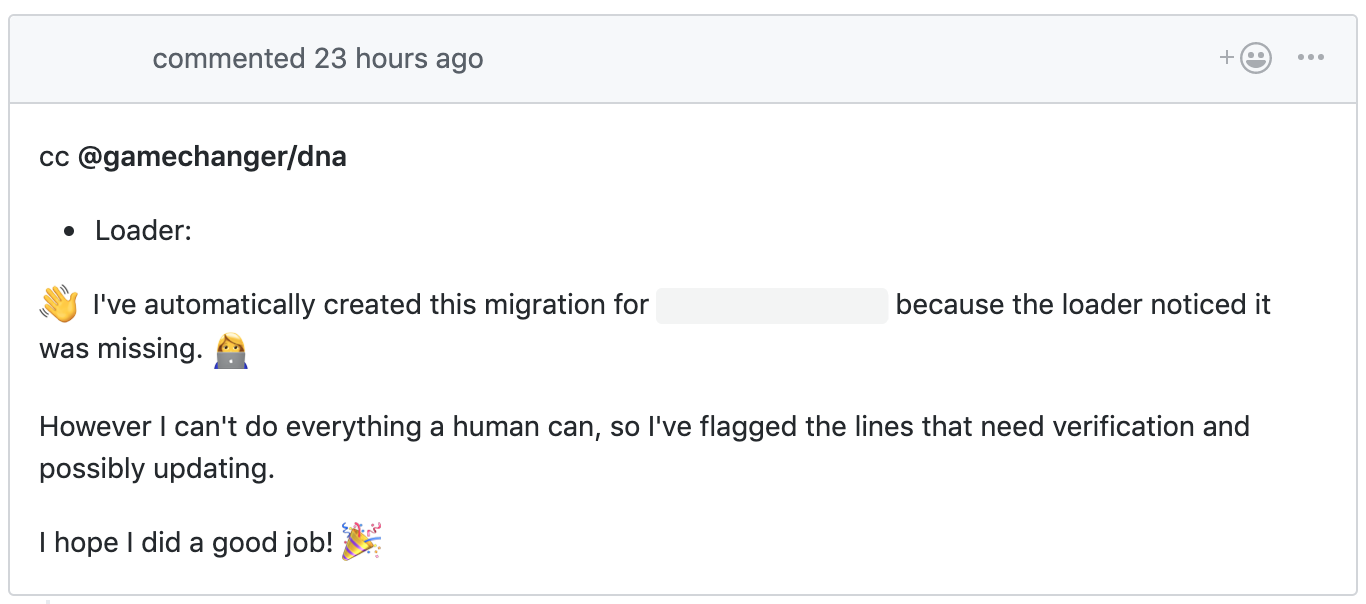
Figure 6.3: personality in automation was achieved using politeness, random emoji selection, and doing work for other people so they don’t have to. It also never forgets to add the data team, nor to link to where it found the table missing.
What have we learned?
So far the only engineer who’s used the system to create tables has been me, but as I write this three new producers are being reviewed that the system will create tables for. The documentation for creating producers has been massively shortened, with the entire section on creating tables replaced with a reminder that while the system will start the pull request, the engineer needs to finish it.

Figure 7.1: how I often feel waiting to see if a thing works in production.
As small as it seems, there’s something to be said for removing that mental burden of switching contexts, writing a SQL CREATE TABLE, thinking through the different options… and instead being asked very specifically, “What is x’s data type? What does it represent?”
For me this has been especially gratifying as, since the day I started, I’ve known this was a pain point for others that I wanted to address. Being a data engineer at GameChanger means overseeing the data pipeline and data warehouse, sure, but it also means knowing a little bit about every system, listening to what my fellow engineers are saying and struggling with, and coming up with ideas that might seem crazy but are doable with a bit of reading the docs, pushing through, and just the right amount of chutzpah. Of the values we hold as a company, the one I associate with most is, “We do unglamorous work in service of the team.” Automating away table creation might have been unglamorous, but it was also satisfying.
Wrap up
I’d like to thank my fellow GameChanger Josh for helping to illustrate this blog post and give it, like my automated pull requests, that little bit of personality to make it shine. I’d also like to thank Eduardo who does the truly unglamorous work of reviewing my pull requests, which are rarely about the same thing two times in a row.
We’re actually looking to hire another data engineer along with a host of other roles in case you’d like to join us. There’s so many great things we do at GameChanger but I can guarantee one thing you won’t ever do, and that’s have to create warehouse tables for your producers.