
Downtime! It’s probably every sysadmin’s least favorite word. But sometimes it’s necessary, and when we’re lucky, we can plan for it in advance, during off-hours, to do some much-needed maintenance.
Whenever we need to do maintenance or an upgrade on our Mongo database, for example, we put the site into “scheduled downtime” mode. The end result for users is that they see a page saying “we’re down for scheduled maintenance, please come back in later” with a link to our status page. If we didn’t do this, users would instead see a blank page, or get lots of 500 errors, or other undesirable behavior.
To accomplish this, we created a tool called Downtime Abbey.
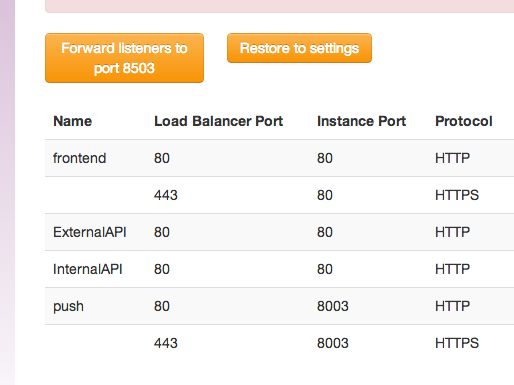
Abbey works by changing our Amazon load balancers to send traffic to a different port. This port is set up to respond with a 503 and the maintenance page- the 503 response (instead of the 500 errors that would otherwise results) tells search engines that this is temporary so they won’t remove our pages from their indexes. The tool uses boto to send all traffic to this downtime port at the beginning of our maintenance windows, and restores the original settings at the end.
In addition, it reconfigures the load balancer health checks. Amazon ELBs have configurable health checks that makes sure each node in the load balancer is healthy, with unhealthy nodes being removed so traffic doesn’t get sent to them. When we’re returning a 503, this causes the health checks to fail, which would cause all the servers to get removed from the load balancer, which would get rid of the maintenance page that users see and display nothing instead. To work around this, Abbey changes the health checks to check a different target (one that returns a 200 OK during maintenance), again changing them back at the end of maintenance, so the load balancers are happy the whole time.
But wait, there’s more!
We use Sensu to monitor all our hosts and services, and naturally during downtime when things are purposely stopped, the checks for these things will fail. We have Sensu configured to send critical alerts to Hipchat, and this used to cause Hipchat to fill up with a lot of red durning downtime.
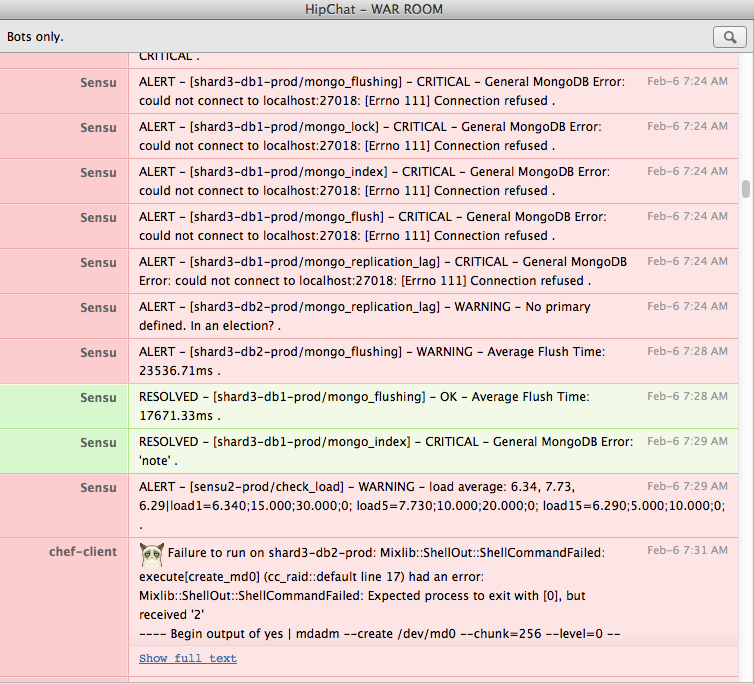
So much red that we almost missed an actual problem in there - the chef-client failure at the bottom indicating that setting up a software RAID array didn’t work properly. Also, alert fatigue is bad, and training ourselves to ignore alerts is bad, so we needed to come up with a way to make these false (or rather, expected) alerts not happen in the first place.
Sensu deals with failures by sending messages to one or more handlers. We have a group of handlers called the ‘default’ group that includes Hipchat, email, Datadog, and PagerDuty. Before, this was hard-coded into the Sensu configuration, but to deal with downtime alerting, we made it an attribute in Chef that we could override as needed.
We created a Chef recipe called sensu::downtime that overrode the list of default handlers to be empty. Failures will still show up on the Sensu dashboard, but they won’t go anywhere else. After changing the handlers attribute, the recipe then restarts the sensu-server service so this change takes effect. Adding this recipe to the run list of the Sensu server overrides the default list (all the handlers) with the empty list, and removing it from the run list lets the defaults stay default (also restarting the service so we start getting alerts again).
But doing that by hand would have been a pain, and one more thing to potentially forget, so PyChef to the rescue! Now, the buttons in the Abbey tool add and remove this recipe from the Sensu server automatically. This means that Sensu is quiet in Hipchat (and PagerDuty) during our scheduled downtime, so we don’t get flooded with red messages we don’t care about. At the press of a button, most of the downtime pain is automatically taken care of… except for the pesky maintenance itself!