
One of the things that we often have to do on the GameChanger tech team, especially now that spring baseball season is approaching, is to bring up more server capacity in AWS to respond to higher traffic. We haven’t yet been able to make use of Amazon’s autoscaling feature that would handle this for us, so we’ve been bringing this extra capacity up and down largely by hand (albeit with extensive help from a script we’ve written to automate away most of the details).
This process has always been rather slow, meaning that we are slower to respond when traffic starts to rapidly increase, so we started looking into how we could speed up the provisioning process.
On Chef
When we provisioned servers, we started with an essentially blank Amazon Machine Image (AMI, or the template from which EC2 instances are created) - it was a basic Linux installation with no GameChanger code or configuration. All of the configuration and deployment was then done using Chef, starting with this base image. Because it was starting from a blank slate, it had to do everything - from installing the user accounts that get installed everywhere, all the way up through the different services that run on our different types of servers (such as Apache on our web servers). This naturally was fairly time-consuming, taking on average 15-20 minutes to bring up one server.
The other problem with doing provisioning entirely with Chef was fragility. If any part of the Chef run failed, the provisioning would stop, leaving the server in a partway-provisioned state that wasn’t able to handle any production traffic, and had to be fixed by an engineer who could diagnose the issue with Chef. An unfortunate side-effect of this was that external dependencies, such as software packages that get downloaded from third-party repositories, could block our provisioning process if they were unreachable.
Chef and AMIs
The great thing about Chef is that after it has set something up, the next time it runs it only has to verify that things have stayed in the correct state. If we’ve created a user account, we don’t have to create it again if it’s still there. If we’ve downloaded a package, we don’t have to download it again. This means that subsequent Chef runs complete much more quickly than the initial run.
So we decided to use this to our advantage by creating our own AMIs from servers that had already completed this initial Chef run. We started out by creating our base AMI, which contained only things that were common to every single server in our infrastructure. This consisted of things like user accounts, environment variables, system tools, and so on, with no application-specific code or settings. We were then able to use this newly-created GameChanger base AMI to provision new servers, which cut several minutes off the provisioning time. Now, initial Chef runs on those servers could breeze over those common parts and only spend significant time on the application-specific parts.
Getting More Specialized
We have several main roles that most of our servers fall into. We have groups of servers for the web frontend, the web and mobile APIs, and servers that do various backend data processing. Each server in a group is identical to any other server in the group, so we decided to leverage those commonalities to create even more specific AMIs. Starting with our newly created base image, we extended our AMI-creation script (because of course we aren’t going to be doing this by hand!) to leverage our existing Chef roles to create a specialized AMI for each type of application server we use.
Because the AMI creation process essentially takes a snapshot of anything that is on the server when the image is created, we did have to be a bit careful with what got baked into these images. Specifically, we made sure that Chef-client wasn’t in the image, to prevent it from getting started a second time on a new server made from this image, and we completely disabled Sensu (our monitoring service) when creating these images, both to prevent re-configuration issues with new servers, and because we don’t want to monitor anything on servers that only exist to create AMIs for other servers.
The Results
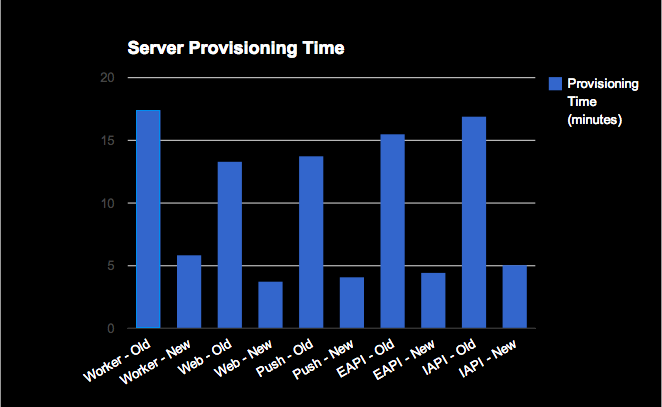
With the exception of our workers (which have many many queues used to process a variety of tasks), we can use these new customized AMIs to provision any of our servers in under 5 minutes. Overall, this came out to be a 70% improvement across the board. Why? Because almost everything that Chef needs to do has already been done, so it doesn’t have to do those things again when it brings up a server from these images. And because our AMIs have all the packages we need already installed, they don’t need to be reinstalled during provisioning of production servers, so we’re much less dependent on external package repositories than we used to be.
Not only will this allow us to be much faster when we need to respond to increased traffic, resulting in a better experience for our customers, we will also be able to leverage these AMIs to make the shift to using Amazon’s autoscaling at some point in the future. Here’s looking forward to a busy spring season and a future post on autoscaling here!