
Engineers often have poor intuition as to what to unit test, so they fall into one of two camps: unit test everything or unit test nothing. Both of these are unhealthy extremes. Unit tests are important, but it shouldn’t be all or nothing. My principle for deciding what code should be tested is that the harder it is to detect bugs during manual regression testing, the more necessary to write automated unit tests.
I’ve been on both sides of this divide. When I worked at Vontu, automated test coverage was measured, and we sought to hit a high target, such as 80%.For a long time, I accepted this as the right way to work, but after a while I started to get the feeling that much of the time I was spending writing tests was wasted.
I also have worked at Amazon.com, which had no institutional policy regarding testing, and at which many teams did no automated testing. Yet Amazon’s availability is very high — for them, not testing everything is working.
My objection to some of the attitudes I’ve encountered is that there is often little logic or principle to them. They seem more based in world view than empiricism. Worse, they are often advocated by people who have always used one method.
I reject the idea that there is a known amount of test coverage you should always strive for. If you have zero customers, your code coverage has produced exactly zero business value. Knowing what should be unit tested will always rely somewhat on intuition, but we can still discuss principles which should guide your team. My philosophy is that test coverage is not valuable in and of itself. It’s a proxy— for achieving quality, customer happiness, and business value, among other things.
At GameChanger, we built a sizable customer base with no unit testing. Now, I’m not recommending this approach. The opposite, in fact. But while shooting for 100% is better than shooting for 0%, it’s still a huge waste of time.
In the past few years, as our UI has become increasingly complex, we have shored up our gaps with automated tests (we use Kiwi to specify behavior), and we write unit and functional tests, in advance, for our new features if they exceed our threshold of needing them.
This threshold is something that many engineers inexperienced with testing struggle with. Test writing is not a part of any CS curriculum I know about, and while books and blogs are a decent way to get started, they only get you so far. Without guidance, you can waste a lot of time, and worse still, write tests that miss the point (e.g. you test that some library code is working, rather than the code you’ve written). It’s mentally easier to have a mandate to cover 80% of your codebase than it is to learn subtle things, but there is a lot of nuance to precisely what needs testing.
We have come to believe that to determine when to spend the effort required to make code testable and write tests, it should be evaluated on how hard it is to discover bugs, rather than defaulting to unit testing or not.
Here I am making the assumption that manual testing is a non-negotiable component of your release process. Even the most die-hard test-first adherents agree that you have to use your app to make sure it works. Details about our development and release cycle were published in a previous post about how to ship an app. In it, you can read about how much we value writing automated functional and unit tests in advance. However, we write those tests in anticipation of how much manual testing effort they save.
To delve into how much automated testing should be done, let’s break the cost of bugs into two types: the cost of being bitten, and the cost to discover.
The cost of being bitten by a bug is what happens to your business value when a bug emerges and affects your customers. A bug which prevents GameChanger users from creating teams is a total disaster, while mis-localizing a field as “postal code” vs. “zip code” is trivial.
The cost to discover is what you had to do to find the bug in testing. Discovering that you cannot create a new team in our app is very easy to discover in manual testing, which has to be done no matter what. On the other hand, making code testable and writing tests represents a cost.
Cost to discover * cost of being bitten is roughly the equation which calculates the risk you take on when you code up new stories. So even when the cost of something going wrong is great, if the cost to discover is very low, the risk is low, and testing is a lower priority.
Example GameChanger Code
In order to make this whole thing concrete, I’m going to show you what I mean with the play editor from the GameChanger Basketball scoring app. I’ll describe our test coverage as it evolved over several releases of the editor to cover cases of made and missed shots being recorded.
Version 3.7
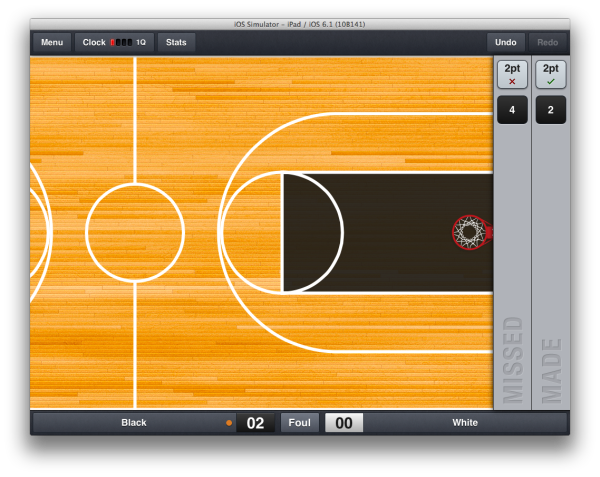
Pictured here is the app immediately after the screen has been tapped on the court area, indicating that a shot was made. On the right is the play editor, showing one play in the play history (made, by player #4), and a new shot, just entered.
The model which is built into the UIViews containing the made/missed button and player number button has only two possible states — shot.made == true or shot.made == false. Detecting an error in manual testing at this stage is trivial; it would not increase my confidence to write a test verifying that the correct PNG file gets displayed for each state.
Version 4.6
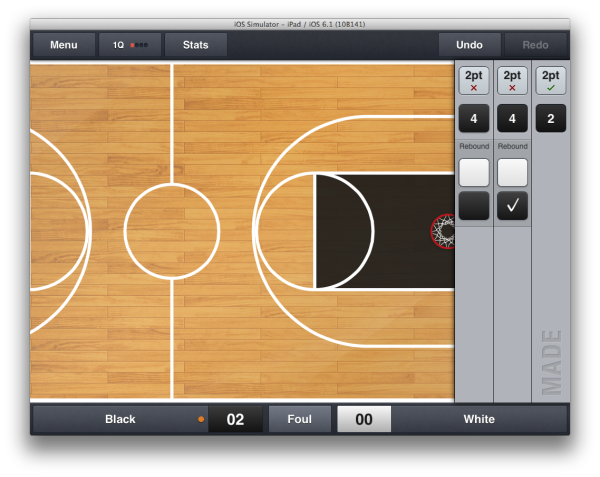
In this version, the model still only has shot.made true and false states, but those states lead to more variety in the views. We’ve added a “segment” (in our lingo, a discrete unit of visual info describing an aspect of a play) for rebounds, which can have either or neither team selected.
Making this code testable, and testing it, is still more effort than it’s worth.
Version 4.7
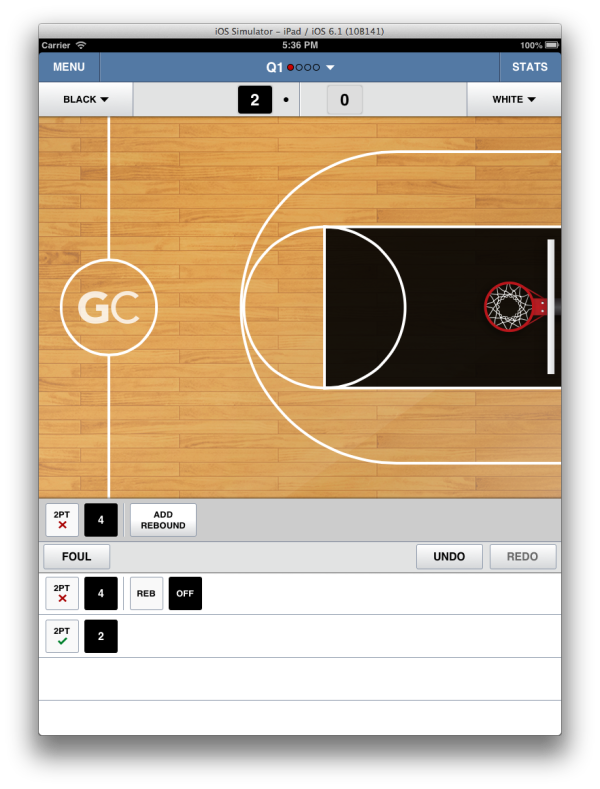
In this version of the app, the play editor moved to the bottom of the screen, and we added a state to the model, so now it has made, missed without rebound, and missed with rebound. It’s still easy to get the app into these states, and we continued to ship this code without unit testing it.
Version 4.8
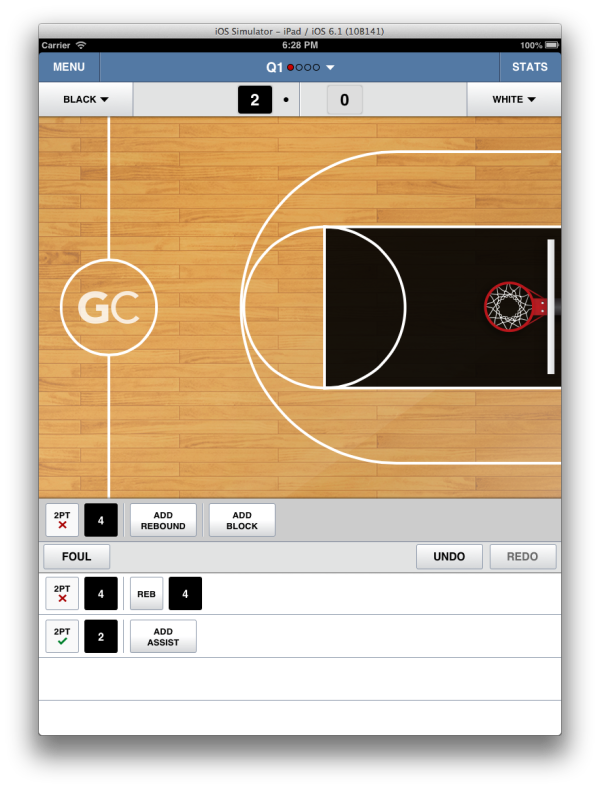
In v4.8, states explode as we added support for assists and blocks in advanced scoring mode, while simple mode remained the same as 4.7.
The play editor would display a segment for adding a block to missed shots and a segment for adding an assist to made shots. Pressing the “add block” or “add assist” button would replace that button with yet another segment, which let you specify the player number for the block or assist. The combinatorics of the values a play’s attributes can have meant lots of states to test.
At this point we added testing for this feature; the time to verify its behavior by manual testing would have inflated by ~10x! In retrospect, I’d have preferred that we added testing for v4.7, but no earlier than that.
Version 5.1 (current behavior as of this post)
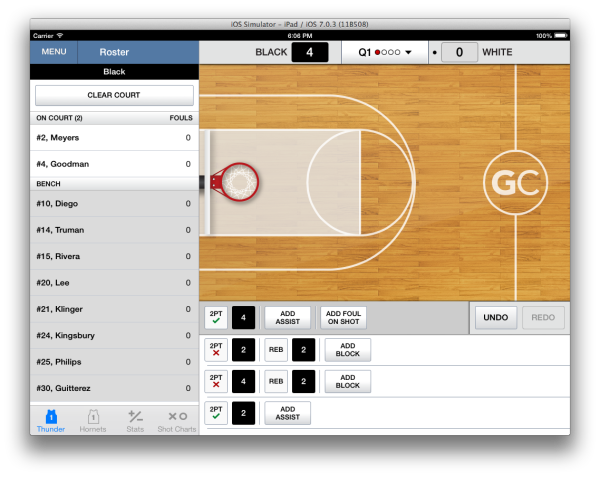
In v5.1 we added support for 3-point and 4-point plays, but fouls can only be added in the editor for the most recent play. At this point there are three states for missed shots (simple, advanced with block, and advanced without block), and made shots have states for current or historical play, simple or advanced with or without blocks, assists, and fouls. Cost to discover bugs without automated testing has skyrocketed, and we have added a robust suite of tests which look like this.
context(@"for a historical play segment with no timeouts before it", ^{
beforeEach(^{
[[manager stubAndReturn: theValue(NO)]
isCurrentPlayManager];
[[manager stubAndReturn: theValue(NO)]
areAllSubsequentRowsTimeouts];
});
it(@"has a shot segment and an add assist segment", ^{
[manager updatePlaySegments];
[[manager should] havePlaySegmentTypes:
@[@(GCPlaySegmentTypeShot),
@(GCPlaySegmentTypeAddAssist)]];
});
context(@"when an assist is added", ^{
beforeEach(^{
manager.event.assistAdded = YES;
});
it(@"has a shot segment and an assist segment", ^{
[manager updatePlaySegments];
[[manager should] havePlaySegmentTypes:
@[@(GCPlaySegmentTypeShot),
@(GCPlaySegmentTypeAssist)]];
});
});The entire file for our Play Editor specs is just shy of 1k lines, so obviously significant time was invested into writing these tests (and the custom matchers we wrote to increase clarity).
I’m trying to move the testing dialogue away from dogma. I think there are cases where automated testing really pays off, and cases where it doesn’t. When you write a test, you’re gambling that the time you take results in saved time and protects you from customer-impacting events, but it’s silly to act as if every gamble has the same odds.
What I’m trying to do is work out where we should place the threshold, and how we should talk about where to place it. Cost of bug discovery is a major component in my process.
I’d really like to hear what other people think; I suspect that either formally or informally, a lot of people who write unit tests are using thresholds, but probably not talking about them.