
At GameChanger we want our APIs to handle requests as quickly as possible. Ideally, they will do a minimal amount of urgent work before returning a response. We have a lot of secondary computation that we want to perform on our data, and we’ve learned to queue any derivative work for later.
Queueing work lets us distribute that work, but also requires that we take some care to ensure data consistency. We use MongoDB as our primary data store, which means no native multi-step transaction ability. As an alternative, Optimistic Locking (described in the MongoDB documentation as Update If Current) is an established strategy for handling distributed processing with light contention on individual documents. To implement it we’ll need:
- Versioning of documents
- Version-specific document updates which fail if the document version in the database has changed
- Handling of failure
We’ve found that with our open source Mongothon library we can make each component of the optimistic locking dataflow a natural part of a Python stack.
The Real World Scenario
One of the services GameChanger provides to coaches is ranking teams in a tournament.
The rankings process is just expensive enough that we’d like to have a queue processor do it and store the results, rather than make a user wait for their web page to load while the rankings get calculated. To simplify matters, let’s say that each team has a 'wins' field and it’s the only data point we use to rank them1. We’ll assume that we’ve already defined our Team and Rankings models, and that Rankings contains a list of relevant teams sorted by their ranking info. Since MongoDB isn’t relational, we’re also going to want to denormalize as much as we can in order to avoid having to fetch all of the teams to perform a re-ranking.
Team({'_id': 1, 'name': 'Yankees', 'wins': 17})
Team({'_id': 2, 'name': 'Mets', 'wins': 5})
Team({'_id': 3, 'name': 'Phillies', 'wins': 16})
Rankings({
'_id': 0,
'teams': [
{'id': 1, 'name': 'Yankees', 'wins': 17},
{'id': 3, 'name': 'Phillies', 'wins': 16},
{'id': 2, 'name': 'Mets', 'wins': 5}
]
})When a team’s 'wins' count changes we’re going to want to update any Rankings document that it’s in. This update will amount to re-sorting the 'teams' list. What we’d like is to do something like
def update_rankings_for_team(rankings_id, team_id):
rankings = Rankings.find_by_id(rankings_id)
team = Team.find_by_id(team_id)
for flat_team in rankings['teams']:
if flat_team['id'] == team['_id']:
flat_team['wins'] = team['wins']
break
rankings['teams'].sort(key=itemgetter('wins'))
rankings.save()If we only have a single queue processor this code will perform perfectly! Unfortunately, this sort of calculation is prone to race conditions when the possibility of concurrent updates is introduced. If the Yankees get one additional win, and the Phillies get three additional wins quickly after, we know that the Phillies should be ahead in the rankings once we finish processing everything. With distributed processing however, we have no control over the order in which we get the new win statistics for a team and re-sort the rankings. Here’s an example of an ordering that would lead to inaccurate rankings if we use update_rankings_for_team as is
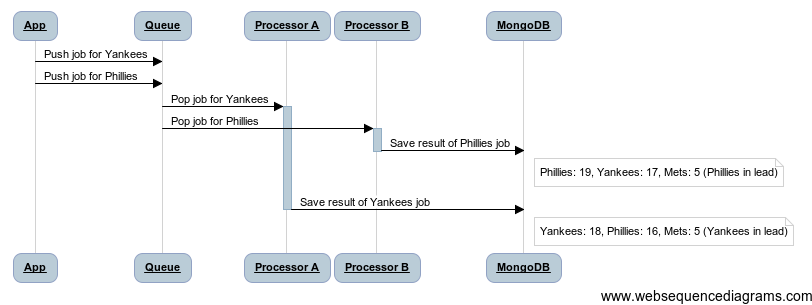
We can make update_rankings_for_team safe for a distributed environment by making it adhere to a concurrency strategy like optimistic locking. Mongothon will let us do this with minimal alterations to our original implementation.
Constraining Updates With The Document Version
Let’s first attach a method to the Rankings model that we can use to bump an instance’s 'version'
@Rankings.instance_method
def bump_version(self):
self['version'] = uuid.uuid4()We’re going to attach another new method to our Rankings model that will act like Rankings.save, but will fail if the underlying document version has changed. Let’s assume that our document is known to already exist in the database2. We’ll eventually call through to Rankings.update3.
class StaleVersionError(Exception):
"""Raised if a rankings save fails due to optimistic locking"""
@Rankings.instance_method
def save_if_current(self):
version = self['version']
self.bump_version()
result = Rankings.update({'_id': self['_id'], 'version': version}, self)
if not result['updatedExisting']:
raise StaleVersionErrorWe can see that if no other process has altered our rankings from the time we fetched it, Rankings.save_if_current() should go through without a hitch. If some other queue processor has altered the rankings, our Rankings.update selector won’t match any documents, and our result will indicate that no existing documents were updated. Note that we have to call rankings.bump_version here; we need to update the version to make sure a concurrent process gets locked out.
Coping With Failure
Our Rankings.save_if_current method does exactly what we want in the success case, but leaves us out to dry a little bit when it fails. We need to retry our rankings update or risk missing out on some important rankings change.
We could try catching the exceptions inside Rankings.save_if_current, but without fetching the latest version from the database we’d just fail again. If we do fetch the latest version from the database, we could try saving again with some likelihood of success, but since we won’t have reevaluated our rankings with the latest player data we’d risk overwriting updates with more up-to-date information.
What would work best would be to just retry the entire queued process (in this case update_rankings_for_team). Python’s decorators are good for this sort of thing.
MAX_RETRIES = 3
def optimistic(function):
@functools.wraps(function)
def retry(*args, **kwargs):
retries = 0
while True:
try:
return function(*args, **kwargs)
except StaleVersionError:
if retries < MAX_RETRIES:
retries += 1
else:
raise
return retryIf a StaleVersionError is raised, we catch it and retry the function call. Our function (and accompanying save_if_current) is likely to succeed on the next go-around, provided that we are in a low-contention situation.
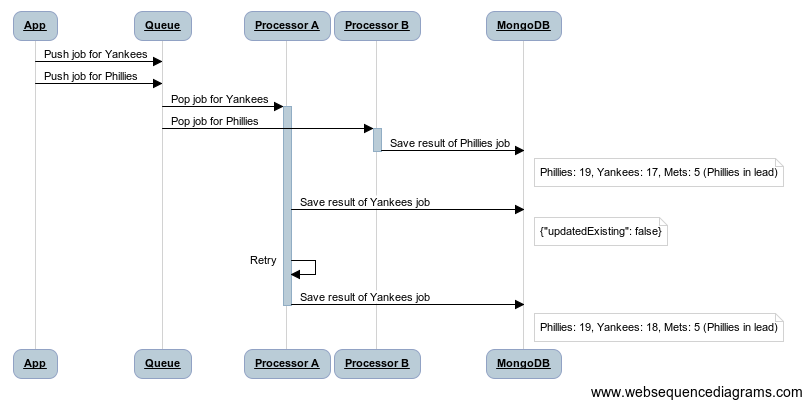
We set a maximum number of retries because it’s possible that we’ve made a mistake in our assessment of the problem space:
- This could be a naturally high-contention situation, in which case the Optimistic Locking strategy is not a good problem fit
- Our concurrent processes could be aligned in such a way that they’re needlessly tripping over each other
Both of these issues will be surfaced by re-raising the StaleVersionError after our maximum number of retries, since either have the potential to make version conflicts appear far more regularly than is appropriate for this data flow.
We now have everything we need to turn update_rankings_for_team into a conflict-free function.
@optimistic
def update_rankings_for_team(rankings_id, team_id):
rankings = Rankings.find_by_id(rankings_id)
team = Team.find_by_id(team_id)
for flat_team in rankings['teams']:
if flat_team['id'] == team['_id']:
flat_team['wins'] = team['wins']
break
rankings['teams'].sort(key=itemgetter('wins'))
rankings.save_if_current()It looks a lot like it did before! We had to add a decorator, and call rankings.save_if_current instead of rankings.save.
There are some production use cases where we have some follow-up business code to run after the save. If we’re sure the post-save stuff won’t alter our rankings data, we could put it in on the next line. In practice however, we’ve found that the save_if_current() line will generally be the last expression in a function (with any follow-up taken care of with Mongothon’s event handling).
Wrap Up
Using a transaction-less database like MongoDB doesn’t mean we can’t replicate transactional behavior. What has become clear to the GameChanger engineering team is that we have to make data consistency with distributed processing easy and accessible. We’ve had the tools for implementing strategies like optimistic locking for quite some time, but until we streamlined them with Mongothon they were something we went out of our way to avoid, at the cost of increased complexity elsewhere in our stack4.
One of the broader takeaways from this is that it is possible to have a team of developers work safely and efficiently if one invests in the development platform itself. It’s easy for us to direct all available engineering time towards adding and improving the features that our users love, while ignoring the foundation that those features are built upon. Allocating development time to the foundation itself can turn out to have direct user-facing benefits when the features they use become more consistent and reliable.
If you’re currently using MongoDB, and are afraid to just let go and implement a real consistency mechanism, now would be a good time to look around the ecosystem a bit. If you’re running a Python service, I suggest checking out Mongothon as a means to a simpler environment for your data.
-
We actually use one of several different algorithms based on the needs of the tournament, which can depend on factors like win percentage and geographic region. ↩
-
To handle “new” documents we’d have to lay down a constraint. New documents must have a unique, deterministic identifier; in the case of two related records like
TeamandRankings, we could have each instance ofRankingsalways have the same'_id'as the organizing tournament. Without this property, we’d have no good way to tell if some parallel process decided to create theRankingsfor our tournament all on its own. OurRankings.updatequery won’t quite work for the case of a new document, so we’d useRankings.insertwhen we know the document didn’t exist prior to our last check. Choosing whether to useRankings.updateorRankings.insertcan be done based on context, or with assumptions about the nature of new documents (e.g. that a new document won’t have a'version'key set). ↩ -
We’re using
Rankings.updateinstead ofRankings.savebecause we need to include our version in our selector query. With MongoDB 2.6.8 and PyMongo 2.8, assuming a Write Concern of “Acknowledged” or higher, we can expect our update to return adictwith'updatedExisting': Trueif the selector matches something, and'updatedExisting': Falseotherwise. ↩ -
See: long sequences of atomic updates with hard-to-find race conditions, bespoke task queue algorithms, convoluted schemas, etc ↩