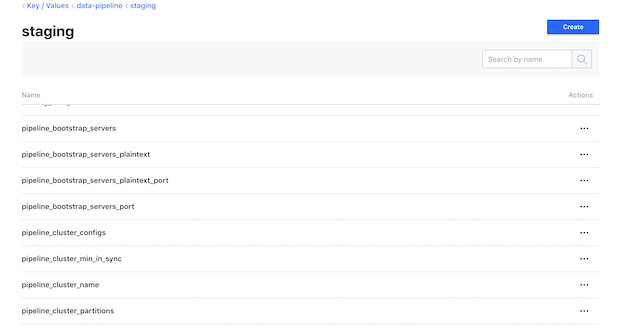
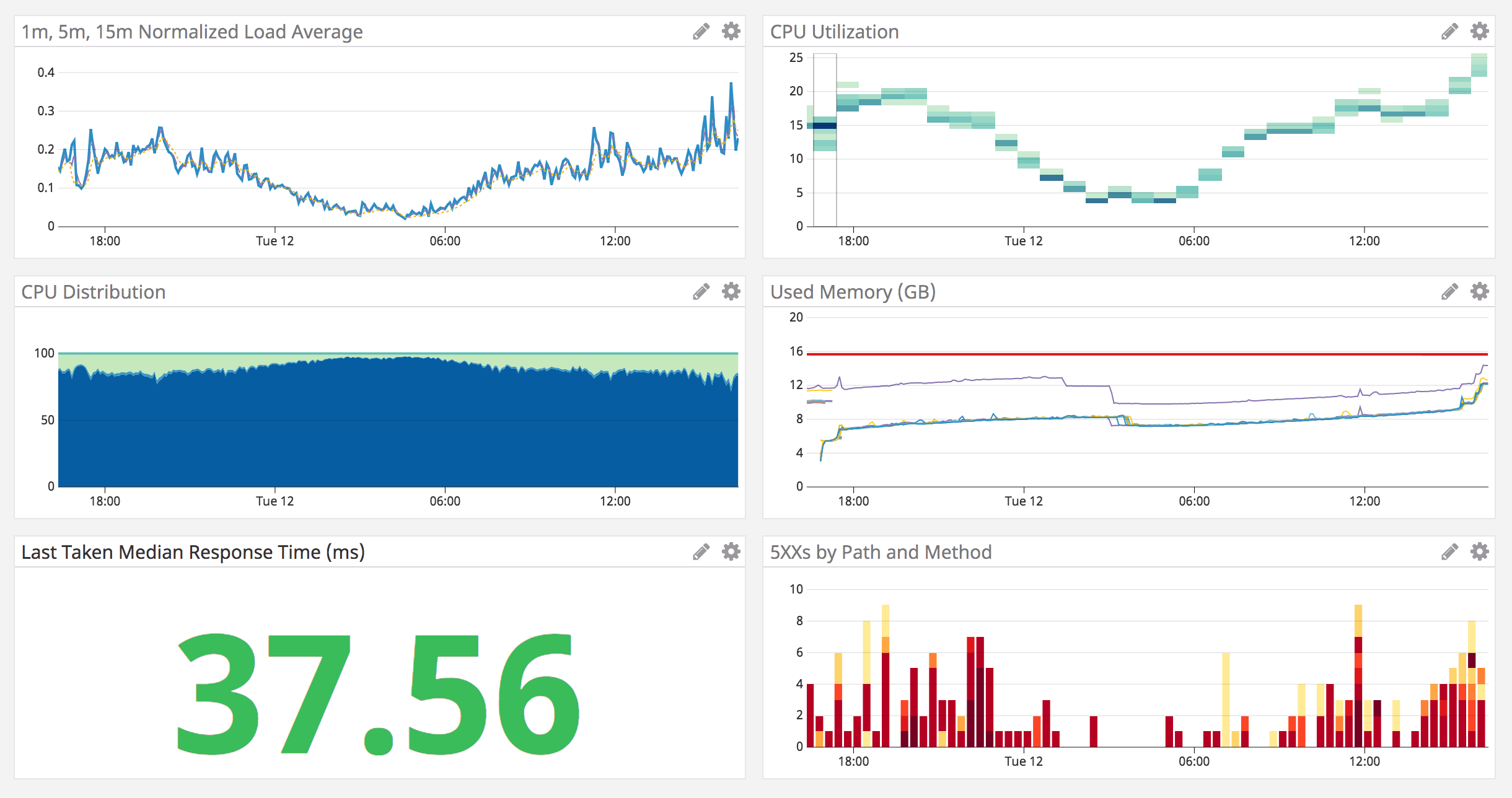
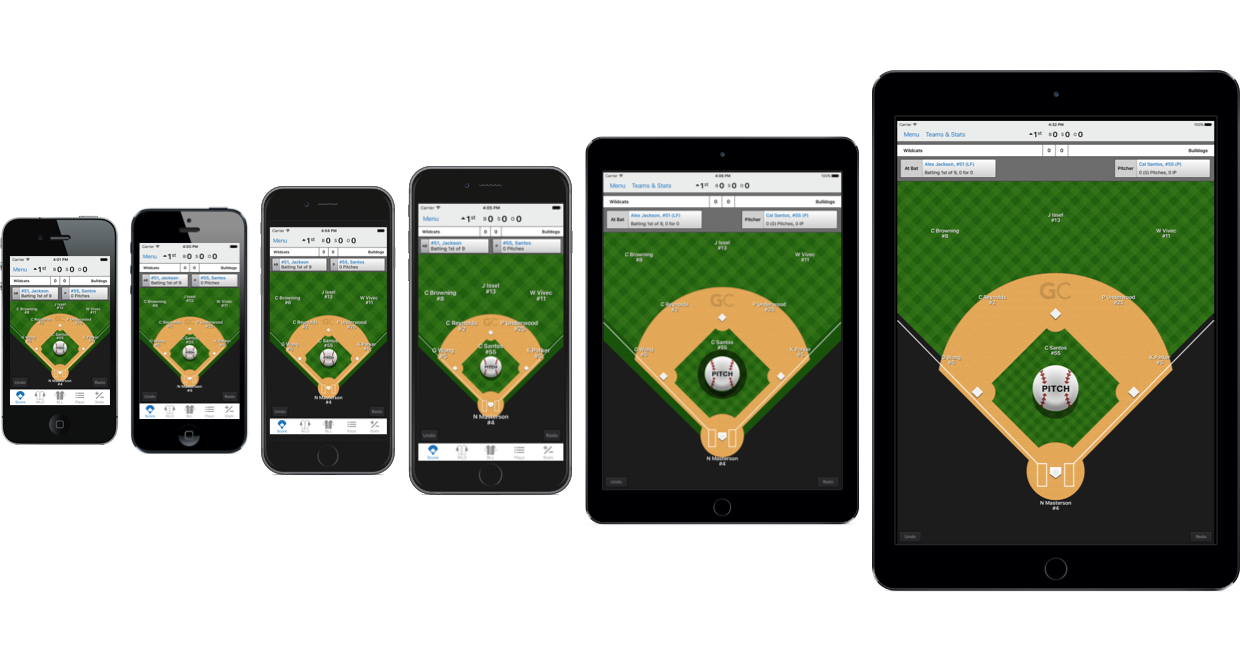
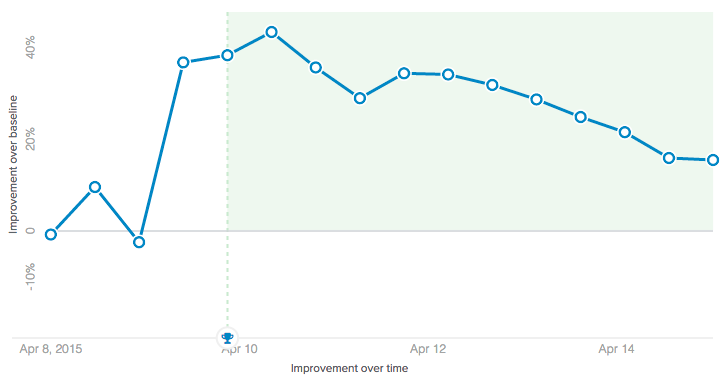
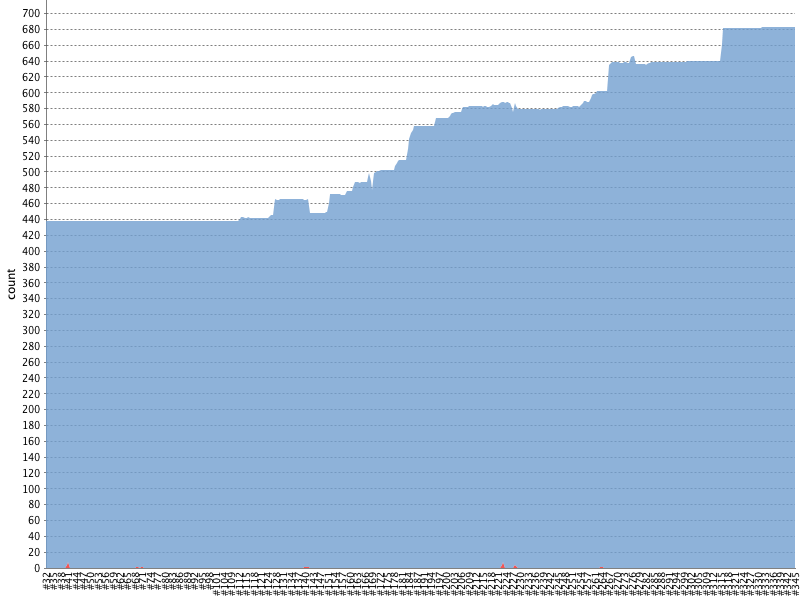
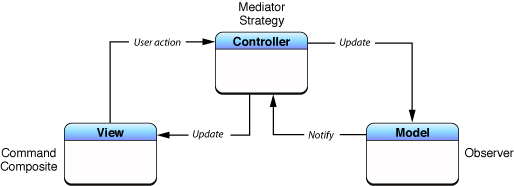
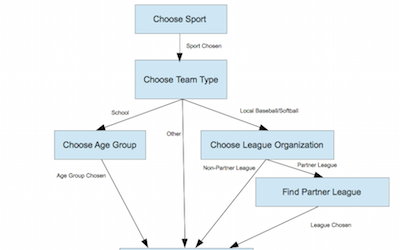
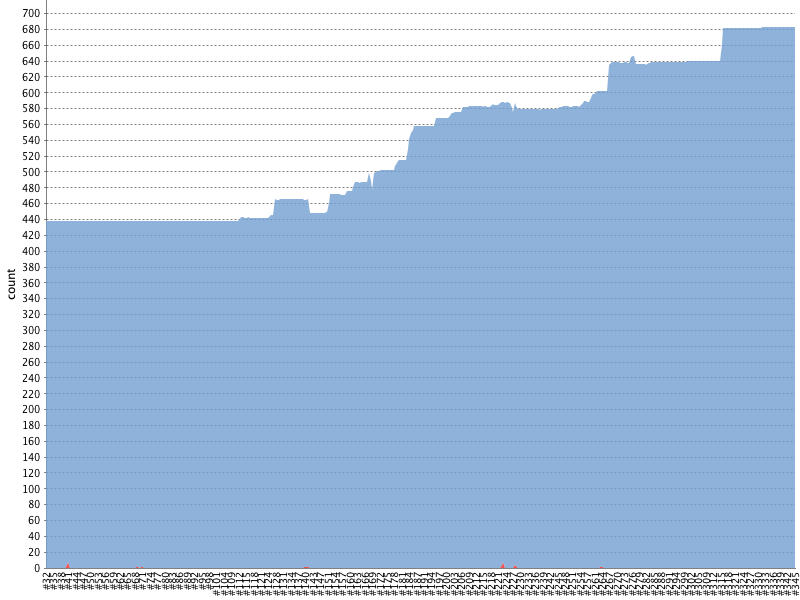
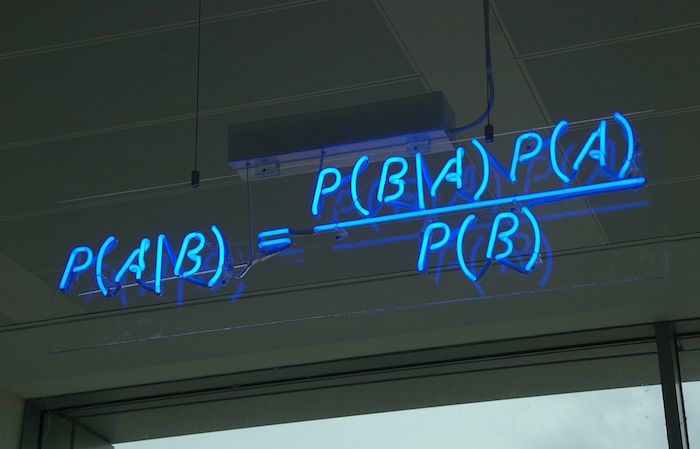GameChanger and Anvil At GameChanger, we have a dedicated App Platform team that focuses on scaling our engineering organization and supporting development teams across the compan... Read More