
An overview of off-the-shelf solutions for moving data out of Kafka, problems we had making those systems work, and how we wrote our own solution and stood it up for those in a similar situation.
You cannot know everything a system will be used for when you start: it is only at the end of its life you can have such certainty. [1]
Many moons ago I wrote about our design for upgrading our data pipeline, which lightly touched on how we’d move data out of our pipeline (Kafka) to downstream systems, namely our data warehouse and data archive. At that time we hadn’t really been able to dive into focusing on getting the data out of Kafka, because getting data in to Kafka is often much more custom and complex, and we thought we’d be able to use an off the shelf solution like Kafka Connect to move data out, don’t even worry about it.
We were, uh — we were wrong.
Let me take you on our journey, in case you’re on this journey too.
- The problem space
- Solution 1: Kafka Connect
- Solution 2: Secor or Gobblin
- Solution 3: we’ll do this ourselves
- How you can do this yourselves, code edition
- How you can do this yourselves, infrastructure and metrics edition
- Takeaways
The problem space
Programmers are not to be measured by their ingenuity and their logic but by the completeness of their case analysis. [4]
At a high level, the problem we needed a solution for was as follows:
- Data enters the data pipeline from numerous backend systems.
- This crossover point is producers into the pipeline, which we’d already implemented.
- Data from the data pipeline needs to move into the data warehouse and the data archive.
- This crossover point would be a consumer on the pipeline.
- Ideally we’d like the same consumer for both needs that we can simply configure differently.
- We want to preserve our data’s Avro format along side its schemas.
- This would allow every system that interacts with the data to use the same language.
- We want to write our data to S3.
- data warehouse: This will be our holding tank where data waits between extraction and loading. (More on this name later.)
- data archive: This will be our archive where data waits until we maybe, one day, thaw it, should it be needed again.
- We’d like to store data based on a timestamp within the event.
- data warehouse: We want to use the processing time.
- data archive: We want to use the event time.
That last item is a really subtle, nuanced one so let me give an example of what I’m talking about: say there was some sort of outage on April 2nd, 2019. Maybe an upstream system hit two unrelated bugs that caused about fifeteen minutes of downtime when they joined forces, you know the kind I mean. The user impact was resolved quick as can be, all of the systems seemed to go back to normal, we all went along with our lives.
Then, in March of 2021, one of our data scientists realizes we’re missing this block of data and it’d be great if we could grab it for them, to fill in this gap for their work. Would that be possible? They’re doing some sort of deep dive so having all the data they can would be :kissing_heart::ok_hand: but no worries if that’s not possible; data will always be imperfect.
Sure thing, we can grab that data! We go to the upstream system and replay the fifteen minutes of missing data, on March 28th, 2021. (I know that implies someone was working on a Sunday but it was my birthday so let me have it.) The data goes into the data pipeline again, ready to move to its downstream systems like nothing ever happened. Where does that data land?
Well for our data warehouse, the data lands in the holding tank to wait to be moved into the warehouse. Because it was processed recently, we put it with other March 28th, 2021 data. For our data archive though, it’s a bit different, as this data was processed recently but is about April 2nd, 2019: you can see that in its event time. If we ever wanted to go back and look at all April 2019 archived data — say for a legal or security request — but the backfilled data wasn’t there with its friends, we’d miss that when we pull data from the archive. And what’s the point of a data archive if you can’t trust that the data is neatly organized to pull from? Our data archive passed 50 TB a long time ago, we can’t sift through it easily by hand, nor can we pull all data from April 2019 until now to compensate for bad sorting in fear that we’d miss something important. That’s no way to live your life.
And that is why we need to store data in the two systems based on different timestamps within the events. We know both fields will always be available (it’s a requirement for our producers to put data into the pipeline) so want to take advantage of that to make sure we keep the data archive tidy and usable. When you shove things in a freezer without labels, you often don’t know what food it is — same problem here when we’re trying to figure out what data we need to thaw from the archive.
So… how do we tackle this problem?
Solution 1: Kafka Connect
Good judgement comes from experience, and experience comes from bad judgement. [2]
If you Google for how to solve this problem (which is possibly how you came across this writeup), the Internet will tell you to use Kafka Connect. And that makes sense: I love being able to use the native, built in solutions a system is meant to work with. It makes your life easier, it’s less maintenance, you’ll probably have much more community support — it’s a win all around! And Kafka Connect can both write data into Kafka and write data out from Kafka, so you can use it in multiple places. We stan a solution that just makes sense.
#!/bin/bash
ENVIRONMENT="production"
KEY_WANT="archive_bucket"
BUCKET_NAME=$(curl https://consul/v1/kv/data-pipeline/${ENVIRONMENT}/${KEY_WANT} | jq '.[0].Value' | sed -e 's/^"//' -e 's/"$//' | base64 --decode)
curl -X PUT -H "Content-Type: application/json" --data '{
"tasks.max": 15,
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.deadletterqueue.context.headers.enable": true,
"errors.deadletterqueue.topic.name": "__deadletter_archiver",
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"s3.region": "us-east-1",
"s3.bucket.name": "'${BUCKET_NAME}'",
"s3.part.size": "5242880",
"topics.dir": "",
"format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
"schema.compatibility": "BACKWARD",
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"timestamp.extractor": "RecordField",
"timestamp.field": "event_ts",
"partition.duration.ms": "7200000",
"rotate.schedule.interval.ms": "7200000",
"flush.size": "1000",
"path.format": "'\''year'\''=YYYY/'\''month'\''=MM/'\''day'\''=dd/'\''hour'\''=HH",
"file.delim": ".",
"topics.regex": "^[^_].*",
"locale": "en",
"timezone": "UTC"
}' https://localhost:8083/connectors/archiver/configA Kafka Connect job assignment we used, here for our production archiver
Except… people have issues with Kafka Connect writing data to S3. There’s just something about that combination that causes it to have issues. I’ll leave you to decide whose accounts online you’d like to read, as it seems we all encountered different though related problems, but what we found over the nearly year and a half we had Kafka Connect running was it would run out of memory no matter what we did, how we changed the configurations, how much memory we gave it, and how we limited the data it was processing. From people who run the system in production to the main authors of the system, no one could figure out or explain why.
Real talk: I’m not hear for that sort of mystery in my systems, especially ones as critical as this one would be. You shouldn’t be either, you deserve better.
When you work with bounded data — a word here which means a finite set of data — you can do things like batch the data for processing and design your solution around the specifics of the data set. But when you’re processing unbounded data — infinite data that just keeps coming, at higher or lower volumes, depending on factors outside your control — you have to be able to handle those ups and downs gracefully.
To understand the limitation of things, desire them. [8]
We wanted a streaming solution — one designed for unbounded data sets — to ensure both that we were moving data as quickly as we could, to deliver insights as quickly as we could, but also to ease the maintenance. It might sound strange, as you’d think a streaming solution would be hella more work to maintain in the long term than a batch system, but in this case it was quite the opposite. The system we’d used in our previous data pipeline was batch based but it was hard to onboard new people to, required a lot of deep knowledge of areas like MapReduce to reason about, and if it got a little bit behind — oof, forget about it, once it hadn’t run for four hours you were about to be in for punishment. One time it was down over the weekend and took a whole week (maybe longer?) to catch up, with single batch runs taking 36+ hours before failing out. Our team took turns having to watch it and keep it running at all hours of the day, and we still had data loss because we weren’t fast enough despite throwing all the hardware we could at it.
There will be large volumes of data, and the data will keep coming. A streaming solution is the right way forward, but Kafka Connect wasn’t ready for the needs we had. So we started to look elsewhere for what other solutions there were. The Internet warned us to write our own solution, but the hope persisted that in this one area, a system already existed that we could use.
Solution 2: Secor or Gobblin
My gracious data engineering partner-in-crime Emma took the lead on looking into two other solutions we’d come across that weren’t as popular as Kafka Connect but could maybe, still, be made to work. I’d like to thank her for her dedication in the great Battle To Make These Systems Work; she was a brave soldier who fought a good fight, which I would not have been able to make it through.
That’s what I consider true generosity: you give your all, and yet you always feel as if it costs you nothing. [7]
Secor was our first contender. It’s from Pinterest, who has some hecka big Kafka clusters, so I trust that their Kafka experts understand what it’s like to run these systems in production in the long term. It was easy enough to get started with but we couldn’t get it to behave as we expected, similar to Kafka Connect. We were seeing strange issues related to codecs, especially around Avro, so someone moving around data without Avro might not face the same challenges. But this for us was a very important requirement so forced us off of Secor to our next item.
Gobblin is the successor to the previous system we’d used for this need, Camus, and yes that does mean we were running Camus years after it was sunsetted, yes it was a scary time I’d like to not think about again. We had thought that Gobblin, while more a batch design, being the evolution of the system we already used, perhaps this would be easy enough to set up and we could tweak it over time. We were still hopeful.
Uh, yeah, so — no. I’m sorry Emma! We spent a week or two intensively working on just seeing if we could make this work — not meet all our needs, purely work. We had trouble with the Avro time partitioning, which had been so easy with Camus. We had constant issues with Gobblin’s Maven dependencies, which was not expected. We couldn’t set the S3 path where the files would be, when it did occasionally put out three files before crashing.
An architect’s first work is apt to be spare and clean. He knows he doesn’t know what he’s doing, so he does it carefully and with great restraint.
As he designs the first work, frill after frill and embellishment after embellishment occur to him. These get stored away to be used “next time.” Sooner or later the first system is finished, and the architect, with firm confidence and a demonstrated mastery of that class of systems, is ready to build a second system.
This second is the most dangerous system a man ever designs. [2]
Yeah, so, the Internet was right all along that we’d need to write our own solution. Would it be something we’d need to maintain? Yes. But would it at least work? We had to hope so!
Solution 3: we’ll do this ourselves
At this point, we had a data pipeline being held up by the need to do two simple, nearly identical things: move data from the pipeline to the archive, and move data from the pipeline to the holding tank. That was it, these were S3 locations, we wanted Avro files, let us specify the timestamps — nothing crazy or out of the ordinary. Simple needs, all configuration based, but none of the off the shelf solutions would work for us and we needed to deliver.
So we wrote our own solution.
I will certainly not contend that only the architects will have good architectural ideas. Often the fresh concept does come from an implementer or from a user. However, all my own experience convinces me, and I have tried to show, that the conceptual integrity of a system determines its ease of use. Good features and ideas that do not integrate with a system’s basic concepts are best left out. [2]
Before I walk you through the solution in detail, let me explain how it came about. See, when Emma and I were discussing what we’d do knowing we needed to write our own implementation, we decided we’d write a Scala consumer using the Kafka native consumer library. Avro and the Schema Registry were also easy enough to throw into the mix, grabbing from Hack Day projects and other one-off scripts we’d used over the years. We decided we’d pair program the implementation and gave ourselves a few days, as I was more familiar with Scala and had a stronger sense of what we’d want to achieve, but we both agreed we needed more than one person to understand the system and be able to maintain it. We cleared our calendars, we made sure people knew we’d be doing Big Things, and then we settled in for several days of intense work.
I’d say about, oh, 40 minutes in, we had 90% of the logic down. :woman_facepalming:
A setback has often cleared the way for greater prosperity. Many things have fallen only to rise to more exalted heights. [6]
Is our solution going to win any awards? No, but that’s fine. We’re not going for a clever solution; in fact, I explicitly didn’t want a clever solution. A clever solution isn’t obvious, a clever solution uses slight of hand and is hard to maintain. What I wanted was a smart solution, a solution that when you look at it you say, “Well of course,” as if there was no other way to logically do this, duh. A smart solution should be so obvious it’s almost painful that you had other iterations before it, but it can take a lot of deep knowledge and work to arrive at such a solution. A smart solution hides the sweat and toil that went into it, but it is the right solution in the long run.
We can replace our solution at any time. We can add to our solution at any time. Anyone on the team can poke about the solution. The solution doesn’t need constant attention. It just is. And that’s what we’d been after this whole time.
Tangent: naming things
But of course, we all know the two hardest problems in computer science are naming things, cache invalidation, and off by one counting errors. However I’ve found a nifty way of naming things that helps to attack this NP-hard problem: poll your coworkers! Not just your team but the whole company! Let everyone brainstorm, especially people who aren’t deeply in the thick of the implementation so can think more freely about what the system is, so it’s name makes sense to them.
Ultimately, the most important part of naming things is just that: meaningful names. As with clever vs smart solutions, there’s a difference in a clever vs smart name, and once you see the smart name, people will assume that was the obvious name from the start. I don’t care if you know what a functor is so long as you can see one in the wild and go, “Yeah I get how that works.” There shouldn’t be barriers to entry making in groups for who understands a system and who doesn’t. What’s the point? You’ve made people feel stupid and excluded, you’ve limited who can and will help you, and for what? A smart name is meaningful to everyone who wants to come along and go, “What’s this? Tell me more.”
I’ve polled people in the past to great results: when we needed a name for the data store where we kept extracted data from the pipeline before loading it into the warehouse, a teammate suggested “holding tank.” Beautiful! Love it! Never been done before! It’s the tank of data that holds stuff waiting to move. It’s specific, it’s meaningful, it’s smart naming.
The finest of pleasures are always the unexpected ones. [9]
So off went the poll for this system: we’re creating a system to sit between the pipeline and the holding tank/archive. It’ll regulate moving data from the one to the other. What should we call it? Shoutout to TJ for suggesting “valve,” a beautiful, succinct name that just fits — so obviously, it’s like it was always meant to be.
We had a name, we had a plan, we had a language in hand. Time to implement!
How you can do this yourselves, code edition
A language that doesn’t affect the way you think about programming is not worth knowing. [4]
Our solution being in Scala had its up and down sides. The upside is, Kafka is very much JVM first and written in a mixture of Java and Scala, so there’s lots of examples online and helpful libraries you can use. Scala also allows you to easily use higher order functions and, being heavily typed, allows you to stub out functions you’ll come back to later. I often find functional Scala works beautifully with test-driven development because you can set up these basic pieces and then, truly, treat each implementation like a black box that just needs to meet your test’s expectations. Having these tests then act as documentation as well as specifications, especially with a given/when/then format which neatly breaks down the test into preconditions, the action being tested, and the postconditions.
test("get value that exists") {
Given("a Consul directory")
val directory = "data-consul-test-directory"
assume(directory.nonEmpty)
assume(!directory.endsWith("/"))
And("a Consul key")
val key = "test_key_1"
assume(key.nonEmpty)
When("I get the value from Consul")
val result = Try(Consul.valueFor(directory, key))
Then("I am successful")
assert(result.isSuccess, s"Result should have been a success but was a failure: $result")
And("the value I expect comes back")
val expected = "this is a test key"
assert(result.get == expected, s"Result `${result.get}` should have matched expected `$expected` but didn't.")
}An example Scala test using given/when/then that was set up before the code it tests was written.
The downside is Scala has a hella steep learning curve. Once you’re in it, it’s pretty smooth sailing, but getting to that point can be difficult. For that reason, I’m going to throw a lot of code at you to assist you and give you a starting point to jump off from. If you want to translate it to Java, go for it, do what makes the most sense for you! If you want to do it in another language, again get wild — you’ll have to live with the implementation and maintenance, so make the choice that is right for you and your team.
It is exciting to discover electrons and figure out the equations that govern their movement; it is boring to use those principles to design electric can openers. From here on out, it’s all can openers. [3]
Domain specific language
Our DSL package contains the building block data structures we use throughout the system. For us, this was most importantly the message data structure to contain our input we take in from the pipeline.
/** Represents a neat, cleaned up message from the pipeline.
*
* @param schema The processed schema that represents this event.
* @param message The contents of this event.
* @param raw The original, raw contents of this event.
* @param timestamp The timestamp for when this event was from, if available.
* @param partition The partition for where this event was from, if available.
* @param offset The offset for where this event was in the pipeline, if available.
*/
case class Message(
schema: ProcessedSchema,
message: Map[String, Any],
raw: GenericRecord,
timestamp: Option[Long] = None,
partition: Option[Int] = None,
offset: Option[Long] = None
) {
/** Returns the timestamp for this message based on the extraction key provided.
*
* @param key The key in the message to get the value with.
* @return Formatted string of the value retrieved.
*/
def extractionStringOf(key: String): String = {
require(message.keys.toSet.contains(key), { s"Cannot extract string using key `$key` when not in message: ${message.keys}" })
val extractionTimestampString = message(key).toString
val extractionTimestampDate = new DateTime(extractionTimestampString, DateTimeZone.forID("UTC"))
Message.dateFormatter.print(extractionTimestampDate)
}
}The ProcessedSchema type here is just a wrapper around the raw Avro schema with some key metadata made easily available, like the name of the schema and a list of its field names, mostly for debugging purposes. Avro is a very concise format, which is great for sending and storing large volumes of messages but not so easy for human eyeballs to make sense of!
One of the big pieces of the message we’ll need for our system is getting the datetime string from the input that we want to use for where we put the message: if it’s from April 2nd, 2019 at 14:00, we need to pull out 2019-04-02 14:00:00 from somewhere to know that! Which key we use is configured when the system gets its assignment, but you can always have more logic around determining that if you want. The formatter can also be made specific to your needs; we use year=YYYY/month=MM/day=dd/hour=HH for historical reasons but you can use whatever you like.
Another key data structure is the messages we’ll output to our deadletter queue about problems the system encountered. This wraps the input message but also provides additional information for debugging later like the error we saw, when we had the issue, who specifically had the problem (in case you have multiple systems outputting deadletters), whatever it is you’d want to know to work on the problem.
/** Deadletter for the deadletter queue, ie message that could not be processed and instead has an error associated with it that requires further investigation.
*
* @param message Message that could not be processed.
* @param exception Error encountered.
* @param processedAt When the message was being processed.
* @param processedBy Name of who was processing it.
*/
case class Deadletter(val message: Message, val exception: Throwable, val processedAt: DateTime, val processedBy: String) {
lazy val asJson: Map[String, Any] = Map[String, Any](
"processed_at" -> Deadletter.dateFormatter.print(processedAt),
"processed_by" -> processedBy,
"exception" -> exception.getMessage,
"topic" -> message.schema.topic,
"message" -> message.message,
"timestamp" -> message.timestamp.getOrElse(null),
"partition" -> message.partition.getOrElse(null),
"offset" -> message.offset.getOrElse(null)
)
}A nice side effect of including the original input is, if we resolve a bug, we can later on send the impacted messages through the pipeline again to its original topic. You can also build out something to track if you keep seeing the same message error out over and over, which might indicate something so broken that it boggles the human brain. I’ve seen some wild data, I bet you have too.
Writing the output
We know ultimately we’ll need to write our messages out as Avro files. This is relatively straightforward though not super obvious if you’re not that familiar with the Avro library’s options. I’m definitely no expert in this area, but I’ve at least gotten the below to work and its generic enough that I’ve used it in a couple of systems.
def write(messages: Seq[Message], fileName: String = ""): Try[File] = Try({
require(messages.map(message => message.schema).toSet.size == 1, { "All messages must be of the same schema." })
val fileNameUse = "tmp/" + {
if (fileName.isEmpty) messages.head.processedSchema.topic
else fileName
}.stripPrefix("tmp/").stripSuffix(".avro").replace("/", "-") + ".avro"
val schema = messages.head.processedSchema.rawAvroSchema
val writer = new DataFileWriter(new GenericDatumWriter[GenericRecord](schema))
val output = new File(fileNameUse)
writer.create(schema, output)
messages.map(message => writer.append(message.raw))
writer.close()
output
})This function will write a local tmp/ file of the passed in messages, assuming they’re all of the same type. Because a message carries metadata about its schema, we can grab the schema from there and make a generic writer that moves our messages from the running system to that local file. This is a very imperative method but I’ve not found a “better” way yet, so if someone is more familiar with the Avro options, please let me know!
(If you’re looking to write JSON output like a deadletter, json4s works beautifully with case classes but can be made to work with generic maps of JSON input quite easily as well.)
Processing the data
Now that we have our handful of building blocks, we can piece them together into our actions we want to take when we have messages. If there is a secret sauce to the system, this is it, so I’m sharing it nearly as is (removing some internal specific comments). Code that’s referenced but I’ve not provided is pretty generic, so you can make your own implementations for things like Log and Metric as you’d like.
/** Perform (business) logic for valve consumption of pipeline messages to move them to data stores. */
object Valve {
/** Generates a file name for a batch of messages using the provided timestamp value for path and file name.
*
* @param timestamp Value to use for timestamp to write messages out using.
* @param messages Messages from the pipeline consumer.
* @return Combined path and file name to use in S3.
*/
def getFileName(timestamp: String, messages: List[Message]): String = {
require(timestamp.nonEmpty, { "Timestamp value must be present" })
require(messages.nonEmpty, { "There must be at least one message in the batch" })
val topic = messages.head.schema.topic
val length = messages.size
val uniqueId = java.util.UUID.randomUUID.toString
s"$topic/$timestamp/${topic}_${length}-messages_${uniqueId}.avro"
}
/** Writes given messages to S3 using provided timestamp value for generating paths and files.
*
* @param s3 Connection to S3 bucket for where to write messages.
* @param timestamp Value to use for timestamp to write messages out using.
* @param messages Messages from the pipeline consumer.
* @return File name wrote to S3.
*/
def writeToS3(s3: S3Connector, timestamp: String, messages: List[Message]): String = {
require(messages.nonEmpty, { "Cannot write empty messages to a file" })
val fileName = getFileName(timestamp, messages)
val file = AvroConverter.write(messages.toSeq, fileName).get
s3.write(fileName, file).get
file.delete
fileName
}
/** Send messages that are associated with an error to the deadletter queue for investigating later.
*
* @param processor Name of processor that encountered these messages, ie name of valve running.
* @param errorTopic Topic to send deadletter messages to.
* @param producer Producer for deadletter messages.
* @param messages Messages that the error is associated with.
* @param exception Error encountered.
*/
def sendDeadletter(
processor: String,
errorTopic: String,
producer: PipelineJsonProducer,
messages: List[Message],
exception: Throwable
): Try[Unit] = Try({
messages
.map(message => Deadletter(processor, message, exception))
.map(deadletter => producer.produce(errorTopic, deadletter.asJson))
.map(result => result match {
case Success(_) => Log.info(s"Wrote to deadletter queue $errorTopic for ${messages.size} messages")
case Failure(exception) =>
Log.error(s"Unable to write to deadletter queue $errorTopic for ${messages.size} messages: ${exception.getMessage}")
throw exception
})
})
/** Action for a pipeline consumer.
*
* @param processor Name of processor consuming these messages.
* @param s3 Connection to S3 bucket for where to write messages.
* @param extractionKey Key to use for timestamp to write messages out using.
* @param errorTopic Deadletter queue topic, if errors are encountered.
* @param errorProducer Deadletter queue producer, if errors are encountered.
* @param messages Messages from the pipeline consumer.
*/
def process(
processor: String,
s3: S3Connector,
extractionKey: String,
errorTopic: String,
errorProducer: PipelineJsonProducer
)(messages: List[Message]): Try[List[String]] = {
val result = Try({
require(messages.nonEmpty, { "Cannot consume empty messages" })
Metric.attempting("process", messages.head.schema.topic, messages.size)
messages
.map(message => (message.extractionStringOf(extractionKey), message))
.groupBy(_._1)
.map(timestampAndWrappedMessages => {
val (timestamp, wrappedMessages) = timestampAndWrappedMessages
(timestamp, wrappedMessages.map(_._2))
})
.flatMap(timestampAndMessages => {
val (timestamp, messages) = timestampAndMessages
Try(writeToS3(s3, timestamp, messages)) match {
case Success(fileNames) => Some(fileNames)
case Failure(exception) =>
Metric.deadletter(exception.getCause.toString, messages.head.schema.topic, messages.size)
sendDeadletter(processor, errorTopic, errorProducer, messages, exception).get
None
}
})
.toList
.sorted
})
result match {
case Success(files) =>
Log.debug(s"Just wrote ${messages.size} messages to: `${files.mkString("`, `")}`")
Metric.succeeded("process", messages.head.schema.topic, messages.size)
case Failure(exception) =>
Log.error("Error encountered consuming", exception)
if (messages.nonEmpty) Metric.failed("process", messages.head.schema.topic, messages.size)
}
result
}
}I know there’s a lot in there but as I said, this is it: this is what makes the system the valve we’re after. You can tweak how you generate file names for your needs, or maybe send more or less metrics than we do. The process function though will probably remain pretty similar to what we have:
- For each batch of messages,
- For each message, get the timestamp we want to use.
- Bucket each group of messages with those who have the same timestamp, for example all of the
2019-04-02 14:00:00messages. - Clean up our
list of (timestamp, messages)to(timestamp, list of messages). - For each timestamp with its messages,
- Try to write the messages to S3.
- If successful, collect the file names.
- Otherwise, send the messages to the deadletter queue.
- Try to write the messages to S3.
- Grab the list of files we wrote and sort them (purely for humans to have an easier time reading).
Everything else is metrics and logs! The data structures provide the necessary extraction functions, and the helper functions provide the rest so each piece is as small as possible: easy to update, easy to test, easy to understand.
Running it
With all of that, all that’s left is to run the system.
object Driver {
def main(args: Array[String]): Unit = {
val configs = Configuration()
val processor = configs.pipelineGroupName
val s3 = S3Connector(configs.bucket)
val topics = SchemaRegistry
.getTopicsToConsume(configs.topicToConsume)
.get
val deadLetterQueueTopic = s"_dead_letter_queue_$processor"
val deadLetterQueueProducer = PipelineProducer.json(processor)
PipelineConsumer(
processor,
topics,
Valve.process(processor, s3, configs.groupByTimestamp, deadLetterQueueTopic, deadLetterQueueProducer),
configs.maxBatch
)
deadLetterQueueProducer.close
}
}You might remember from my blog post about only having to specify configurations once that we use Consul to share values. This allows each piece of our system (like pipeline consumers and producers) to grab the configurations they need, so our Configuration object only needs to grab the environment variables specific to this valve, like which bucket will it write the data to or which timestamp are we grouping by. Then, once the pieces are set up, we pass the pipeline consumer our processing function and the rest takes care of itself.
(I have choosen to omit the pipeline consumers and producers as they are very basic implementations you can make using the default Kakfa drivers. My only suggestion is do allow the consumer to take in a function it applies to each batch of message — this allows you to use the same consumer code in multiple systems with minimal changes in between. Here we also use the Schema Registry to figure out which topics are of interest to us, but you might have another way of specifying that.)
How you can do this yourselves, infrastructure and metrics edition
Alright, we have a valve, it works well enough to throw it into the wild and see how it behaves. We even have some metrics around it, so like: now we launch it, yeah? How do we launch it though?
We like to use AWS ECS on Fargate (read more about our running Apache Airflow on it here) for our data systems so I’ll let that description suffice for this blog post as well for how we run containers. The major difference between that setup of Terraform to run containers and what the valve has is scaling: the valve is constantly running, trying to keep pace with data, so we want to make sure we have enough valves for the data we’re seeing. Since Kafka works with consumers to distribute messages, all we need to do is scale the consumers in the group and Kafka will organize distribution of messages. Thanks, Kafka!
The programmer, like the poet, works only slightly removed from pure thought-stuff. He builds his castles in the air, from air, creating by exertion of the imagination. [2]
We’ve chosen to scale on three metrics: offset lag (if we’re more than so many messages behind), time lag (if we’re more than so many hours behind), and memory usage (as the final backup though we’ve yet to see this really be necessary). The offset lag and time lag we calculate in our consumer and report to AWS, looking at the difference between messages we’re just consuming and where the most recent data is; for example, if we’re processing a message from 06:00 today with an offset 973 and right now it’s 17:32 with the latest offset for this topic/partition being 10452, we’re over eleven hours behind and nearly a thousand messages behind. Time to scale on time lag!
Within our Terraform module, we use the following generic scaling policies that we configure as necessary with min/max instances, offset lag (for us, 25 batches behind), time lag (two hours behind), and memory usage (60%). This way each version of the valve (one for extracting, one for archiving, always room for more!) can scale on its own but we can also have them configured similarly, since they’ll all be flooded at the same time with the same messages. It’s easier for us to mentally reason about the system this way while allowing each to do its thing in its own time and way.
resource "aws_appautoscaling_target" "valve-scaling-target" {
service_namespace = "ecs"
resource_id = "service/${var.pipeline_cluster_name}/${aws_ecs_service.valve-service.name}"
scalable_dimension = "ecs:service:DesiredCount"
max_capacity = var.max_instances
min_capacity = var.min_instances
}
resource "aws_appautoscaling_policy" "valve-scaling-policy-offset-lag" {
name = "${var.environment} ${var.purpose} scale on message offset lag"
policy_type = "TargetTrackingScaling"
service_namespace = aws_appautoscaling_target.valve-scaling-target.service_namespace
resource_id = aws_appautoscaling_target.valve-scaling-target.resource_id
scalable_dimension = aws_appautoscaling_target.valve-scaling-target.scalable_dimension
target_tracking_scaling_policy_configuration {
target_value = var.target_offset_lag
scale_in_cooldown = var.scale_cooldown_up
scale_out_cooldown = var.scale_cooldown_down
customized_metric_specification {
metric_name = "max_offset_lag"
namespace = var.service
statistic = "Average"
dimensions {
name = "CONSUMER_GROUP"
value = var.purpose
}
dimensions {
name = "ENVIRONMENT"
value = var.environment
}
}
}
}
resource "aws_appautoscaling_policy" "valve-scaling-policy-time-lag" {
name = "${var.environment} ${var.purpose} scale on time lag"
policy_type = "TargetTrackingScaling"
service_namespace = aws_appautoscaling_target.valve-scaling-target.service_namespace
resource_id = aws_appautoscaling_target.valve-scaling-target.resource_id
scalable_dimension = aws_appautoscaling_target.valve-scaling-target.scalable_dimension
target_tracking_scaling_policy_configuration {
target_value = var.target_time_lag
scale_in_cooldown = var.scale_cooldown_up
scale_out_cooldown = var.scale_cooldown_down
customized_metric_specification {
metric_name = "max_time_lag"
namespace = var.service
statistic = "Average"
dimensions {
name = "CONSUMER_GROUP"
value = var.purpose
}
dimensions {
name = "ENVIRONMENT"
value = var.environment
}
}
}
}
resource "aws_appautoscaling_policy" "valve-scaling-policy-memory-usage" {
name = "${var.environment} ${var.purpose} scale on memory usage"
policy_type = "TargetTrackingScaling"
service_namespace = aws_appautoscaling_target.valve-scaling-target.service_namespace
resource_id = aws_appautoscaling_target.valve-scaling-target.resource_id
scalable_dimension = aws_appautoscaling_target.valve-scaling-target.scalable_dimension
target_tracking_scaling_policy_configuration {
target_value = var.target_memory_usage
scale_in_cooldown = var.scale_cooldown_up
scale_out_cooldown = var.scale_cooldown_down
predefined_metric_specification {
predefined_metric_type = "ECSServiceAverageMemoryUtilization"
}
}
}At this point with the valve up and running, monitoring the system is actually super simple! We like to use the same style boards for most of our systems, so if the below Datadog examples look familiar, it’s because you’ve seen me use these before.
We must trust to nothing but facts: These are presented to us by Nature, and cannot deceive. We ought, in every instance, to submit our reasoning to the test of experiment, and never to search for truth but by the natural road of experiment and observation. [10]
Looking at our last month in production, I can see what our valve has been up to:
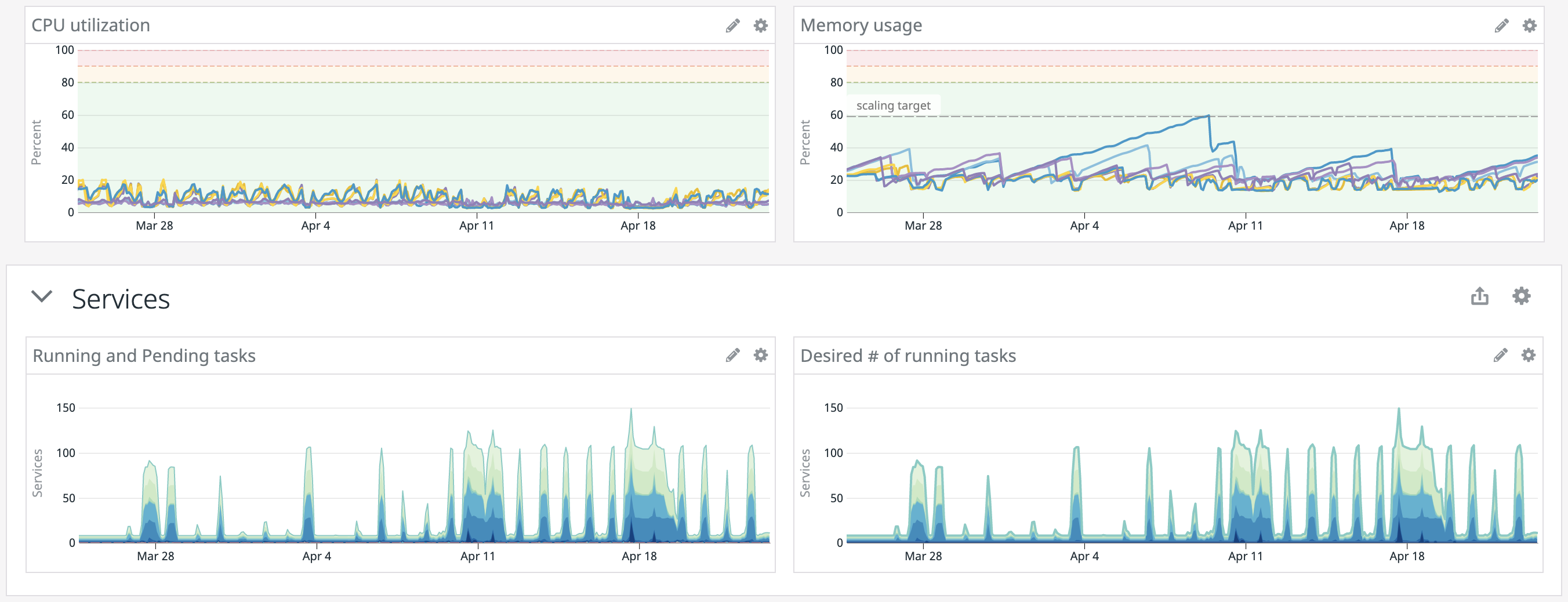
CPU and memory usage have been typically low, excellent, and that makes sense: the system is data intensive but not doing anything complicated. We can also see the pickup in data coming in based on our running or pending tasks; as a sports company, weekends and nice weather are often quite clear in our metrics about what our data systems are up to. We’re constantly tweaking our max instance limit as well as offset/time lag scaling policies, to make sure we’re moving the data through our systems as quickly as we can, so this is always exciting to drill into on Monday morning to see if we were aok or need to give the system more room to scale or make it more sensitive to prevent falling behind and then, worse, staying behind.
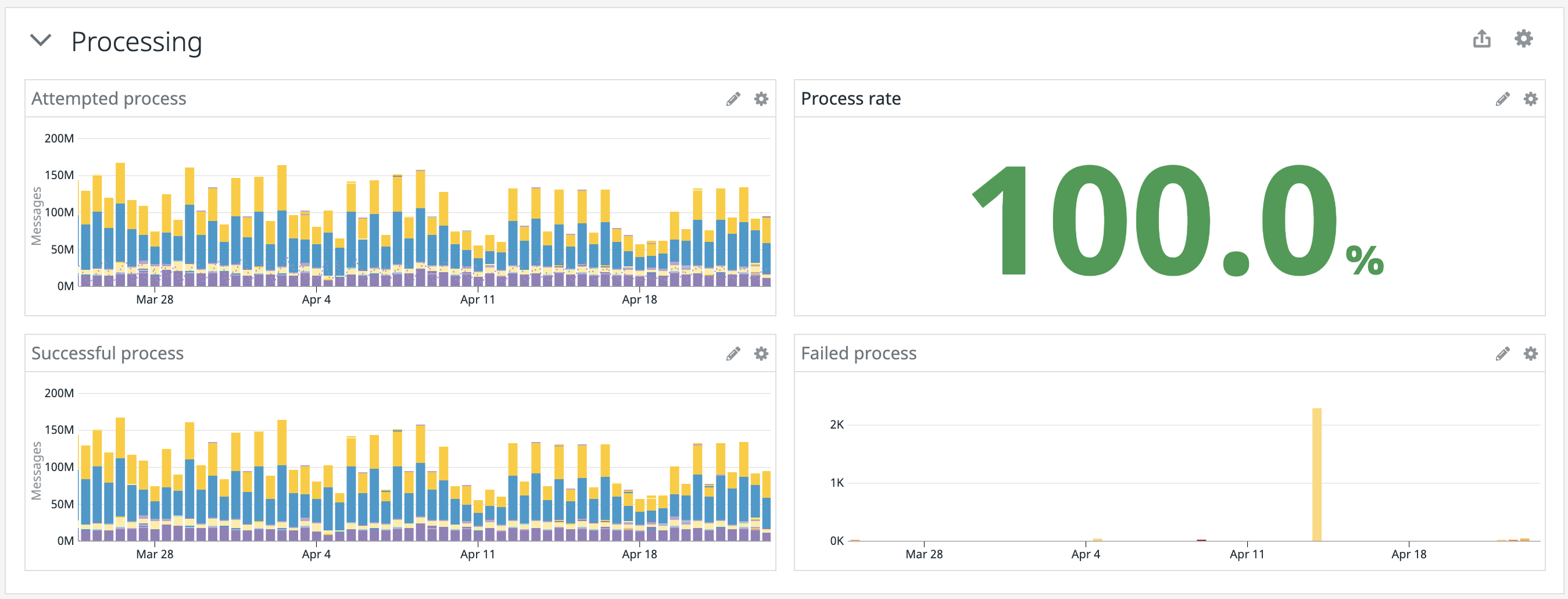
When we looked at processed messages (so messages that hit the Valve.process function and what happened from there), there’s a lot happening all the time! :fr: Formidable! :fr: We do have a spike in failed processes to look into, but that’s super rare and — given the scale of messages — it’s actually so small that it doesn’t bring down our success rate.
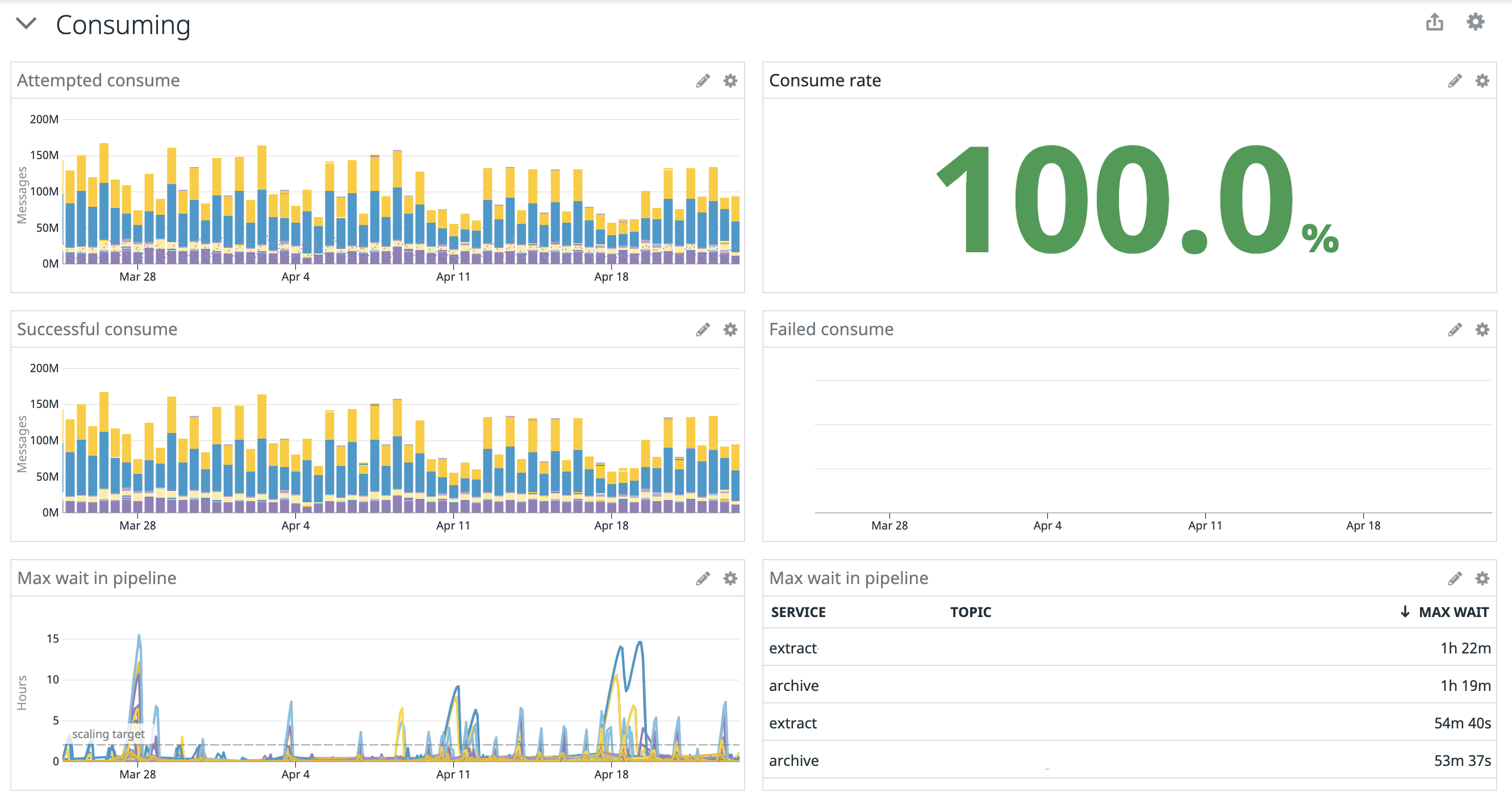
Similar to the processed metrics, the consumed messages (when the Kafka consumer picks up messages and if there’s an issue in that handoff), there’s the same amount of messages flowing through but none of them fail to be consumed. We do see our max wait in the pipeline keeps peaking way over our scaling, meaning that while we’re scaling, we’re not necessarily doing it fast enough or early enough; certain topics are more impacted by this than others (names removed but I promise they’re there on the real dashboard). Your scaling patterns might differ from ours so humans can respond more quickly during the week, whereas our load happens while no one is working. Gotta keep Mondays spicy.
Takeaways
So, uh, hate to say it, but the Internet was right from the start on this one: for moving data from Kafka to other systems, especially S3, writing your own custom solution remains the best way forward. And that can be daunting! Especially if the Kafka native libraries aren’t that familiar to you, or Kafka itself is a relatively new system.
All programmers are optimists. [2]
My hope is that, by providing so much detail of our thought processes, our code, our setup and monitoring, I can make taking on this problem and writing your own solution not only less daunting but something you feel confident tackling. A system like the valve might be complicated to describe but its implementation is small, obvious, and can be fully covered in automated tests to ensure both that you know what your code is doing and that others will be able to understand and maintain it as well.
Since rolling the valve out, we’ve had no problems that come to my mind outside of purely tweaking the scaling of the system. Again, given that our data is very seasonal and high load tends to come when we’re not working, getting our scaling just right is a long learning curve that we’re used to from every system that scales.
And the valve has, thankfully, started to pave the way for making use of the newer features our updated Kafka provides us. It shows that now we can not only make huge, data intensive systems that keep pace with the flow of data through the data pipeline, we can do it with just a little, straightforward code that anyone can hop into. If you want to start transforming data in real time, we can do it — no more batch jobs that take hours! If you want to start building customer-facing features that don’t slow down the main RESTful backend server, we can do it — and you have all the data available to you! The only limit, really, is your ability to figure out what you want to do with all this power.
We can only see a short distance ahead, but we can see plenty there that needs to be done. [5]
This journey took a year and a half to come to its conclusion but it was worth it: our new data pipeline was rolled out so smoothly, no one knew we’d torn down the old one until we announced that we’d already done it weeks ago. In our ETL process, the extractor is the fastest system with the least number of errors. If anything, the main problem with the valve is that it is so fast, the systems downstream from it look incredibly shabby and slow in comparison. Maybe time to redo those systems, to make them as quick and responsive as the valve is.
I’d like to thank Emma and Eduardo for their help in working with Kafka Connect, Secor, Gobblin, and the valve. I’d also like to thank the entirety of the data team for their help in running Camus manually during our largest extractor incident, and their faith that if I said we were going to write our own Scala solution, that that was the right way forward and I’d make the team feel comfortable with it. And finally I’d like to thank Jason, who never lost faith that Data Engineering would figure it out, even (and especially) when Data Engineering was just me, floundering, doing the best I could.
Time to convert another batch system to a streaming solution!
Footnotes
- Siobhán Sabino, “When You Deserve Better Systems”, yes I am now quoting myself from a blog post where I quoted myself.
- Frederick P. Brooks Jr., Mythical Man Month.
- Neal Stephenson, Cryptonomicon.
- Alan J. Perlis, “Epigrams on Programming”.
- Alan Turing, “Computing Machinery and Intelligence”.
- Seneca, Letters from a Stoic.
- Simone de Beauvoir, All Men Are Mortal.
- Lao Tzu, Tao Te Ching.
- Erin Morgenstern, The Night Circus.
- Antoine-Laurent de Lavoisier, Elements of Chemistry.