
At GameChanger(GC), we recently decided to use Kafka as a core piece in our new data pipeline project. We chose Kafka for its consistency and availability, ability to provide ordered messages logs, and its impressive throughput. This is the second in a series 2 blog posts I will be doing that describe how we found the best Kafka configuration for GC. My first blog post discussed learning about Kafka through experimentation and the scientific method.
In this blog post I am going to address a specific pain point I saw in our Kafka setup: adding and removing boxes from the Kafka cluster. I will start by examining the Kafka system and pain points I faced. Next I will present a series of iterations that made the scaling process easier and easier. Finally, I will show how our current setup allows for no hassle box management.
To explain the problems I was facing with scaling Kafka, I need to give some background on how Kafka boxes (brokers) work. When a new box starts up, a broker.id must be specified in the server.properties file for that box. Immediately this presents a set of problems that need to be addressed. As mentioned in some of my other blog posts, I set up our Kafka boxes using AWS’ auto scaling feature. This means all of the boxes are essentially identical. How do I specify a different broker.id for each box, if they all run the same launch config? This problem makes just launching Kafka boxes hard.
The solution I developed was to create a distinct broker.id based off of the box’s IP. This guaranteed uniqueness between boxes and allowed each new box to easily get a broker.id. To do this I added a bash script to the Kafka Docker image. The script is below:
FOURTHPOWER=`echo '256^3' | bc`
THIRDPOWER=`echo '256^2' | bc`
SECONDPOWER=`echo '256^1' | bc`
ID=`curl https://169.254.169.254/latest/meta-data/local-ipv4`
FOURTHIP=`echo $ID | cut -d '.' -f 1`
THIRDIP=`echo $ID | cut -d '.' -f 2`
SECONDIP=`echo $ID | cut -d '.' -f 3`
FIRSTIP=`echo $ID | cut -d '.' -f 4`
BROKER_ID=`expr $FOURTHIP \* $FOURTHPOWER + $THIRDIP \* $THIRDPOWER + $SECONDIP \* $SECONDPOWER + $FIRSTIP`The script gets the IP of the machine using AWS’ metadata endpoint. It then constructs a 32 bit broker.id from this IP. This was a workable first step, and allowed me to launch as many new boxes as I wanted. But I still had issues.
In order to explain these issues, I need describe how Kafka partitions work. To do this I need to define some terms:
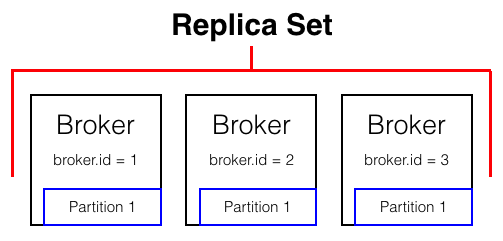
- Broker - box with a unique
broker.id - Partition - smallest bucket size at which data is managed in Kafka
- Replication Factor - # of brokers that have a copy of a partitions data
- Replica Set - set of brokers that a partition is assigned to live on
- In Sync Replicas - brokers in the replica set whose copy of the partition’s data is up to date
When a partition is created, it is assigned to a replica set of brokers. This replica set does not change. For example, If I were to create a new partition with replication factor 3 that ended up on brokers 1, 2, and 3, the replica set be brokers 1, 2, and 3. If broker 1 were to crash, the replica set would stay 1, 2, and 3 but the in sync replicas would shrink to 2 and 3.
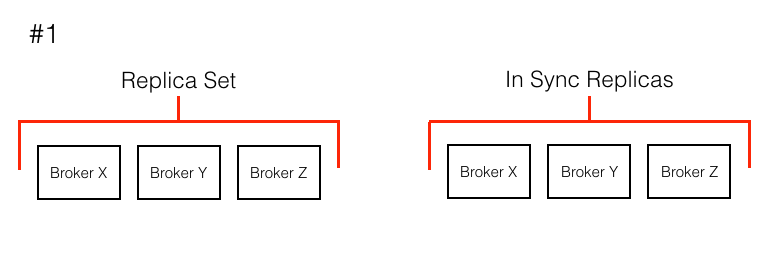
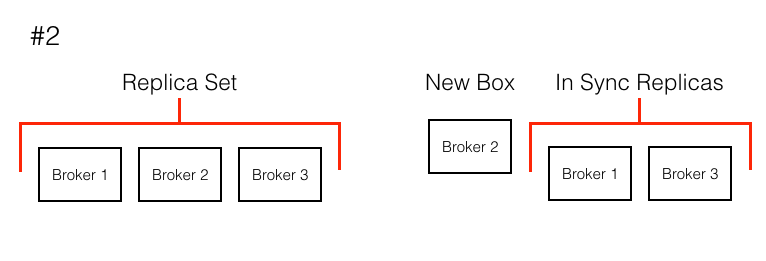
So why is this implementation detail a pain point for Kafka? Imagine the following scenario: (See the visual below)
- One of our boxes on AWS was marked for retirement and needed to be replaced with a new box in our cluster.
- The way we were doing box names meant we were replacing a box with broker.id X with a box with broker.id A.
- If broker X is replaced with A, the partition whose replica set is X,Y,Z does not change. Its in sync replicas just goes from X,Y,Z -> Y,Z.
- The new broker A, does not join the replica set and does not start helping with load. In essence the new box does nothing.
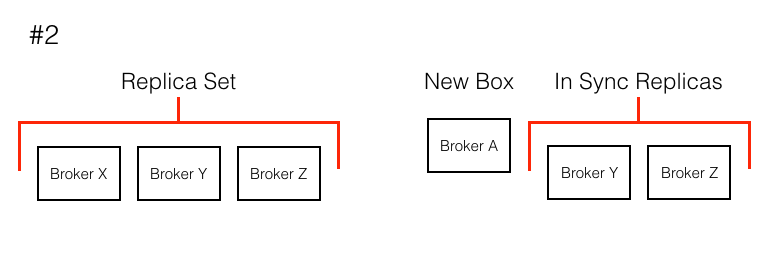
In order to enable A to start doing work in the cluster, I had to run a time consuming and confusing script. To combat this issue, I could have manually given the new box the same broker.id as the old box, but that defeats the idea of an autoscaler. What could I do?
I needed a better algorithm to define the broker.id. I switched form using the bash script using an IP -> broker.id mapping to using the following python script:
import os
from kazoo.client import KazooClient
zk = KazooClient(hosts=os.getenv('ZOOKEEPER_SERVER_1'))
zk.start()
zk_broker_ids = zk.get_children('/brokers/ids')
set_broker_ids = set(map(int, zk_broker_ids))
possible_broker_ids = set(range(100))
broker_id = sorted(possible_broker_ids - set_broker_ids)[0]
print broker_idThis algorithm checks with the zookeeper cluster to get all current boxes. It then gets the lowest broker.id that is not taken by a different box. This simple algorithm change makes all the difference for ease of scaling.
Lets go back to a scenario where I needed to replace a box. I had boxes 1,2,3 and killed box 2. When the autoscaler launched a new box, the broker was assigned the lowest available broker.id (2). After startup, the new broker 2 saw that it should have had the data that the old, removed broker 2 had. It then began to sync itself into the cluster, to get full copies of all the data, and eventually became a leader of some of the partitions. All of this happens with no manual work from developers! (See the visual below)
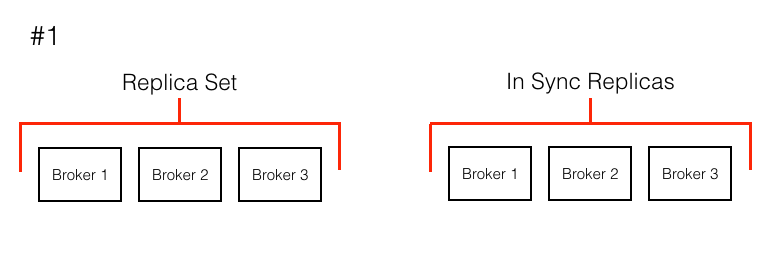
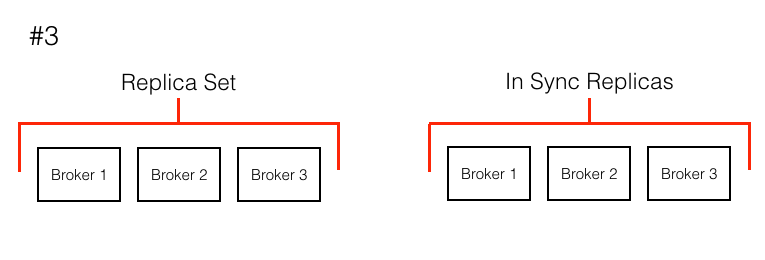
I was getting to a place where switching out boxes and growing the cluster was becoming very easy. There was still a limiting factor though: time to sync in a node. Going back to the scenario where there are 3 boxes with broker.id 1,2,3 and say each box had upwards of 1 TB of data on it. Box 3 now dies. It was very slow for new broker 3 to sync into the cluster and for the cluster to get back to a completely safe state. Could I shorten this time?
The answer was obviously yes, and to do it I needed to use two different technologies: AWS’ Elastic Block Store(EBS) and Docker volume mounts. EBS allows for specification of an independent storage device that can attach to an EC2 box. So if I had a Kafka box running, I could mount an EBS volume at / on that computer. I could then ensure that Kafka was writing all of its data to / using Docker volume mounts. All the data written to / will actually be written to the EBS volume. In a pinch, I could manually take that EBS volume, detach it from the box, and mount it on another machine. Suddenly, I had the ability to take all the data from a box that was shutting down and move it to a new box quickly!
Through a series of steps and improvements, it is now fast, simple, and easy to scale our Kafka infrastructure. When there is so much else I have to put my attention on, scaling boxes should be kept out of site and out of mind. I recommend taking similar steps in your own cluster to make scaling Kafka easy.